-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
在使用ARL(Asset Reconnaissance Lighthouse资产侦察灯塔系统,项目地址地址为https://github.com/TophantTechnology/ARL)的时候,有两个问题比较困扰我:
1. ARL使用Fofa导入数据的时候怎么降重?
2. 如何自己手动编写Poc?
在网上查阅了一些相关资料后,我发现并没有有师傅写的很清晰,于是诞生了写这篇文章的想法。
这篇文章不涉及ARL的基础搭建过程和基础使用过程,如果您之前没有使用过ARL,详情可以参考官网教程:https://tophanttechnology.github.io/ARL-doc/system_install/
先说结论,是由于Fofa_api的限制而不是ARL本身的问题
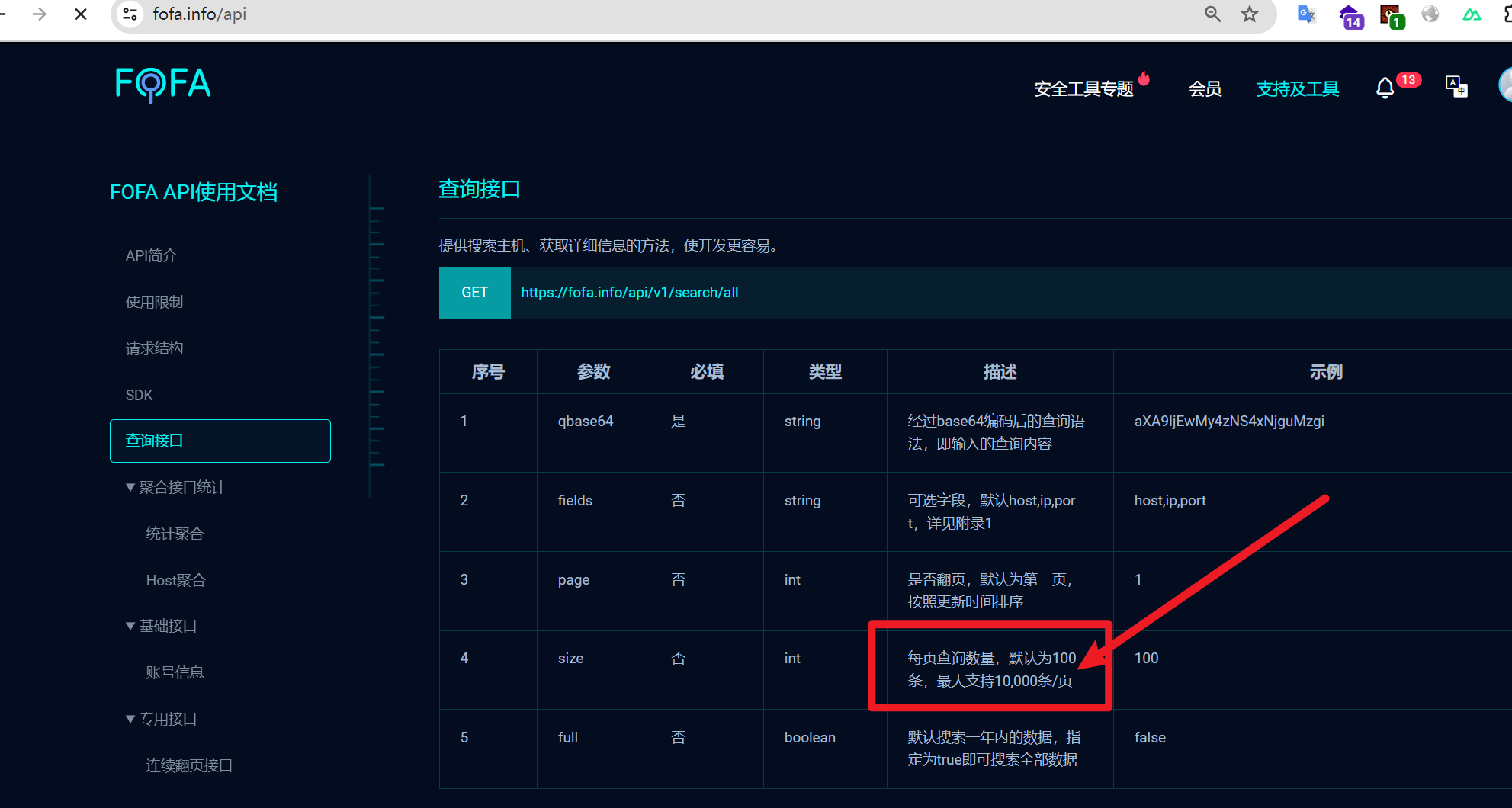
来源于我之前的使用体验,使用同样的Fofa语句,比如能搜到大量地的资产,但是ARL只会跑几千条,然后我们反复运行发现得到的资产结果是一致的,这样就大大地影响了配合Fofa使用好处,只能自己更换不同的Fofa语句来实现降重,非常麻烦。
首先我们先黑盒看看调用fofa的流程:
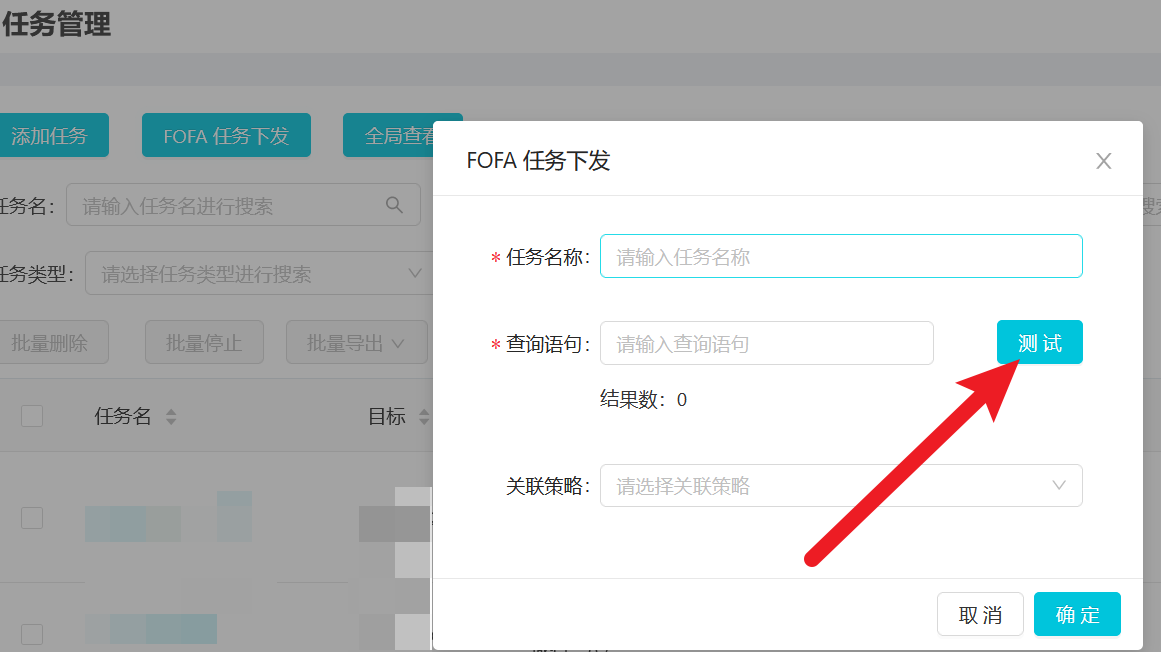
POST /api/task_fofa/test HTTP/2
{"query":"org=\"China Education and Research Network Center\""}HTTP/2 200 OK
{"message": "success", "code": 200, "data": {"size": 13492282, "query": "org=\"China Education and Research Network Center\""}}可以看见这里返回的结果是13492282条
然后我们直接去项目里面去找:
路径为:ARL-2.6.1\app\routes\taskFofa.py
from flask_restx import Namespace, fields
from app.utils import get_logger, auth, build_ret, conn_db
from app.modules import ErrorMsg, CeleryAction
from app.services.fofaClient import fofa_query, fofa_query_result
from app import celerytask
from bson import ObjectId
from . import ARLResource
ns = Namespace('task_fofa', description="Fofa 任务下发")
logger = get_logger()
test_fofa_fields = ns.model('taskFofaTest', {
'query': fields.String(required=True, description="Fofa 查询语句")
})
.route('/test')
class TaskFofaTest(ARLResource):
.expect(test_fofa_fields)
def post(self):
"""
测试Fofa查询连接
"""
args = self.parse_args(test_fofa_fields)
query = args.pop('query')
data = fofa_query(query, page_size=1)
if isinstance(data, str):
return build_ret(ErrorMsg.FofaConnectError, {'error': data})
if data.get("error"):
return build_ret(ErrorMsg.FofaKeyError, {'error': data.get("errmsg")})
item = {
"size": data["size"],
"query": data["query"]
}
return build_ret(ErrorMsg.Success, item)
add_fofa_fields = ns.model('addTaskFofa', {
'query': fields.String(required=True, description="Fofa 查询语句"),
'name': fields.String(required=True, description="任务名"),
'policy_id': fields.String(description="策略 ID")
})
.route('/submit')
class AddFofaTask(ARLResource):
.expect(add_fofa_fields)
def post(self):
"""
提交Fofa查询任务
"""
args = self.parse_args(add_fofa_fields)
query = args.pop('query')
name = args.pop('name')
policy_id = args.get('policy_id')
task_options = {
"port_scan_type": "test",
"port_scan": True,
"service_detection": False,
"service_brute": False,
"os_detection": False,
"site_identify": False,
"file_leak": False,
"ssl_cert": False
}
data = fofa_query(query, page_size=1)
if isinstance(data, str):
return build_ret(ErrorMsg.FofaConnectError, {'error': data})
if data.get("error"):
return build_ret(ErrorMsg.FofaKeyError, {'error': data.get("errmsg")})
if data["size"] <= 0:
return build_ret(ErrorMsg.FofaResultEmpty, {})
fofa_ip_list = fofa_query_result(query)
if isinstance(fofa_ip_list, str):
return build_ret(ErrorMsg.FofaConnectError, {'error': data})
if policy_id and len(policy_id) == 24:
task_options.update(policy_2_task_options(policy_id))
task_data = {
"name": name,
"target": "Fofa ip {}".format(len(fofa_ip_list)),
"start_time": "-",
"end_time": "-",
"task_tag": "task",
"service": [],
"status": "waiting",
"options": task_options,
"type": "fofa",
"fofa_ip": fofa_ip_list
}
task_data = submit_fofa_task(task_data)
return build_ret(ErrorMsg.Success, task_data)
def policy_2_task_options(policy_id):
options = {}
query = {
"_id": ObjectId(policy_id)
}
data = conn_db('policy').find_one(query)
if not data:
return options
policy_options = data["policy"]
policy_options.pop("domain_config")
ip_config = policy_options.pop("ip_config")
site_config = policy_options.pop("site_config")
options.update(ip_config)
options.update(site_config)
options.update(policy_options)
return options
def submit_fofa_task(task_data):
conn_db('task').insert_one(task_data)
task_id = str(task_data.pop("_id"))
task_data["task_id"] = task_id
task_options = {
"celery_action": CeleryAction.FOFA_TASK,
"data": task_data
}
celery_id = celerytask.arl_task.delay(options=task_options)
logger.info("target:{} celery_id:{}".format(task_id, celery_id))
values = {"$set": {"celery_id": str(celery_id)}}
task_data["celery_id"] = str(celery_id)
conn_db('task').update_one({"_id": ObjectId(task_id)}, values)
return task_data其中有一个类和俩函数在其他地方:
# -*- coding:UTF-8 -*-
import base64
from app.config import Config
from app import utils
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__)
class FofaClient:
def __init__(self, email, key, page_size=9999):
self.email = email
self.key = key
self.base_url = Config.FOFA_URL
self.search_api_url = "/api/v1/search/all"
self.info_my_api_url = "/api/v1/info/my"
self.page_size = page_size
self.param = {}
def info_my(self):
param = {
"email": self.email,
"key": self.key,
}
self.param = param
data = self._api(self.base_url + self.info_my_api_url)
return data
def fofa_search_all(self, query):
qbase64 = base64.b64encode(query.encode())
param = {
"email": self.email,
"key": self.key,
"qbase64": qbase64.decode('utf-8'),
"size": self.page_size
}
self.param = param
data = self._api(self.base_url + self.search_api_url)
return data
def _api(self, url):
data = utils.http_req(url, 'get', params=self.param).json()
if data.get("error") and data["errmsg"]:
raise Exception(data["errmsg"])
return data
def search_cert(self, cert):
query = 'cert="{}"'.format(cert)
data = self.fofa_search_all(query)
results = data["results"]
return results
def fetch_ip_bycert(cert, size=9999):
ip_set = set()
logger.info("fetch_ip_bycert {}".format(cert))
try:
client = FofaClient(Config.FOFA_EMAIL, Config.FOFA_KEY, page_size=size)
items = client.search_cert(cert)
for item in items:
ip_set.add(item[1])
except Exception as e:
logger.warn("{} error: {}".format(cert, e))
return list(ip_set)
def fofa_query(query, page_size=9999):
try:
if not Config.FOFA_KEY or not Config.FOFA_KEY:
return "please set fofa key in config-docker.yaml"
client = FofaClient(Config.FOFA_EMAIL, Config.FOFA_KEY, page_size=page_size)
info = client.info_my()
if info.get("vip_level") == 0:
return "不支持注册用户"
# 普通会员,最多只查100条
if info.get("vip_level") == 1:
client.page_size = min(page_size, 100)
data = client.fofa_search_all(query)
return data
except Exception as e:
error_msg = str(e)
error_msg = error_msg.replace(Config.FOFA_KEY[10:], "***")
return error_msg
def fofa_query_result(query, page_size=9999):
try:
ip_set = set()
data = fofa_query(query, page_size)
if isinstance(data, dict):
if data['error']:
return data['errmsg']
for item in data["results"]:
ip_set.add(item[1])
return list(ip_set)
raise Exception(data)
except Exception as e:
error_msg = str(e)
return error_msg诶?我看到这个代码的时候我感觉他这里写的没有毛病,那么我的疑问变得更重了,为什么我查询的结果明明有一千万多条,但是实际到我们的项目条数就几千条:
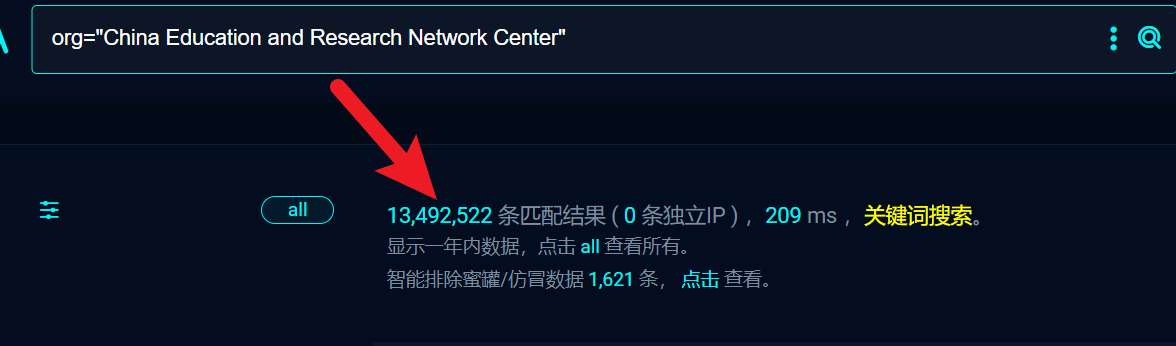

conn_db('task').insert_one(task_data)根据上面这条代码,于是我进入了docker容器,查看了数据库的具体信息:
大致数据就是下面这种格式:
"fofa_ip" : [ "xxx.xxx.xxx.xxx", ], "celery_id" : "xxx", "statistic" : { "site_cnt" : 3935, "domain_cnt" : 0, "ip_cnt" : 2590, "cert_cnt" : 0, "service_cnt" : 0, "fileleak_cnt" : 3068, "url_cnt" : 0, "vuln_cnt" : 94, "npoc_service_cnt" : 0, "cip_cnt" : 0, "nuclei_result_cnt" : 0, "stat_finger_cnt" : 167, "wih_cnt" : 0 } }这里对应的fofa_ip数量与我在前端上面看到的数量一致,我就纳闷了为什么这里就只有这么几千条IP数量呢?我准备把这部分的代码手动抽出来在我本地上跑一遍试试看看结果到底是什么?
我在本地运行后发现返回的ip数量是由page_size决定的,如下面的代码
def fofa_query_result(query, page_size=9999):
try:
ip_set = set()
data = fofa_query(query, page_size)
if isinstance(data, dict):
if data['error']:
return data['errmsg']
for item in data["results"]:
ip_set.add(item[1])
return list(ip_set)我将page_size改为20000,发现根本不返回结果了,这里我才想起来回到Fofa_API的官网去查看,发现了是API一次只能返回最多10000条的限制。

那么解决办法是什么呢?
我们可以看到Fofa Api这里存在一个翻页参数,我们的改进措施就是让ARL使用Fofa API的时候增加一个翻页参数而不是不添加导致每次都是第一页。面向大众的话,要我们一个一个去修改源代码是不太现实的,我这里将给原作者发起一个issue,期待他的更新。
最简单的措施就是我们改进一下Fofa语句:
(status_code="200" || banner="HTTP/1.1 200 OK") && org="China Education and Research Network Center"避免过期资产误杀:

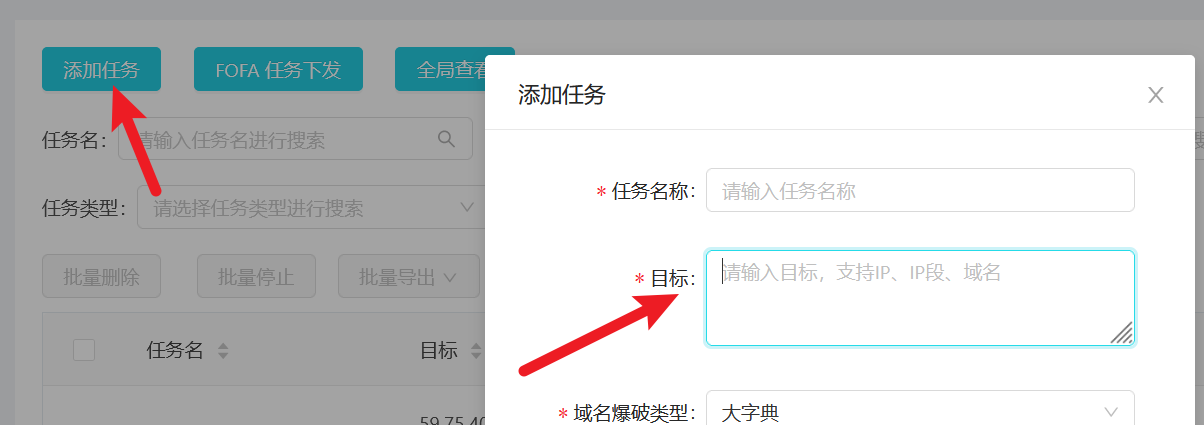
这里是有20万多条独立IP,我们可以利用Fofa_api先把这20多万条独立IP下载下来,使用ARL本身的添加任务功能将这些IP填进去,这样的缺陷就是不能跑Poc,要跑Poc的话可以等待我们这20多万的数据跑完一遍后,然后直接风险任务下发选择对应的Poc就可以了。
添加任务的时候使用下列的格式加入:
IP1
IP2
IP3
IP4
IP5
IP6
...
想要优雅地使用ARL,会自己编写更新Poc是必不可少的。
ARL的poc工具在路径/opt/ARL-NPoC/xing/plugins/poc中我们后续在这个路径去修改,我们可以从作者的仓库看看这个工具:https://github.com/1c3z/ARL-NPoC
这里需要单独注意一点,我们在安装的时候
pip3 install -r requirements.txt 这里最后一个PyYAML直接安装会报错,我们直接使用下列命令直接安装。
pip install PyYAML然后安装运行:
pip3 install -e .就可以使用了:
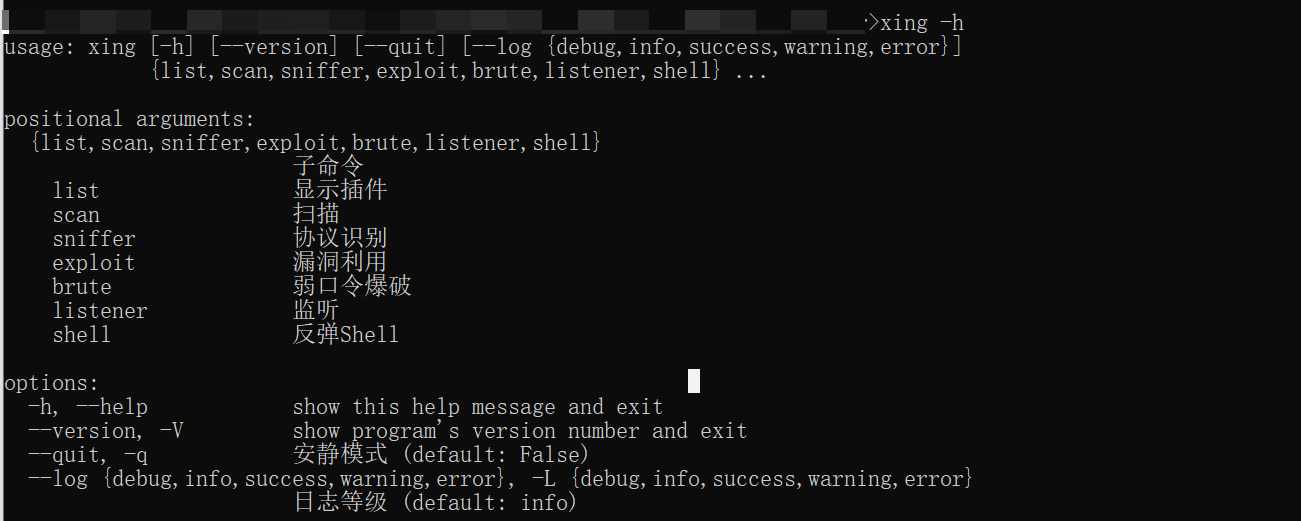
大致使用教程:
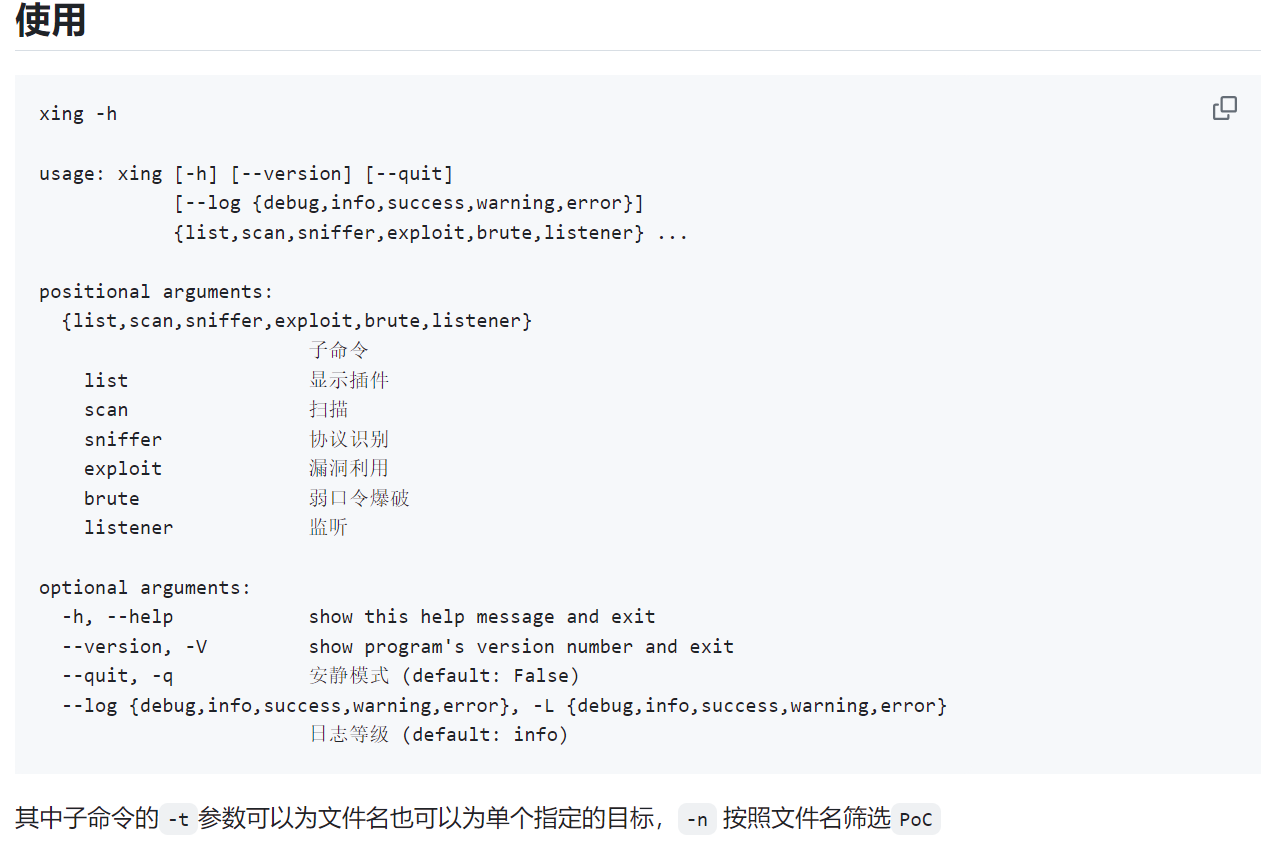
这里我拿直接ARL给我扫出来的一个弱口令进行验证:
xing brute -t 目标地址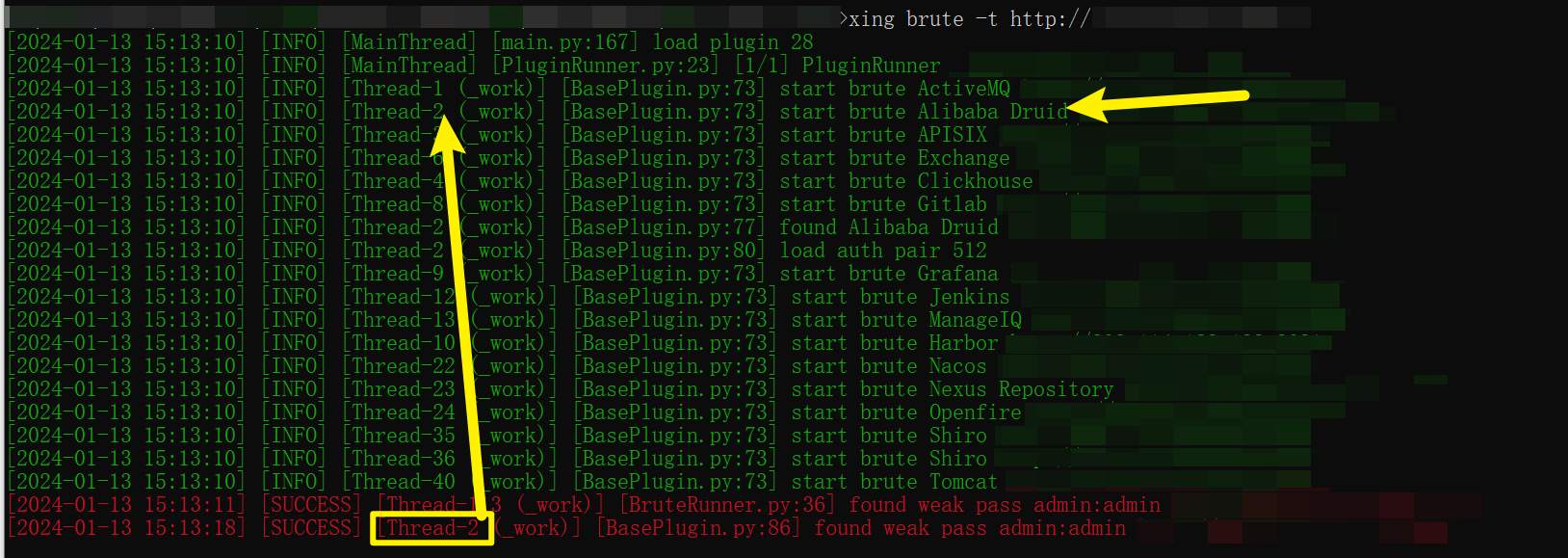
然后我们就可以开始编写Poc了
我们来分析一个较为简单的但是很实用的Actuator API 未授权访问漏洞的POC:
from xing.core.BasePlugin import BasePlugin
from xing.utils import http_req
from xing.core import PluginType, SchemeType
class Plugin(BasePlugin):
def __init__(self):
super(Plugin, self).__init__()
self.plugin_type = PluginType.POC # 定义该插件的类型便于后续调用
self.vul_name = "Actuator API 未授权访问"
self.app_name = 'Actuator'
self.scheme = [SchemeType.HTTPS, SchemeType.HTTP]
def verify(self, target):
paths = ["/env", "/actuator/env", "/manage/env", "/management/env", "/api/env", "/api/actuator/env"]
for path in paths:
url = target + path
conn = http_req(url)
if b'java.runtime.version' in conn.content:
self.logger.success("发现 Actuator API 未授权访问 {}".format(self.target))
return url 主要流程就是先定义一个插件的类,然后使用函数__init__(self)写出这个插件的一些信息,具体实现过程在verify函数中实现。
这里我就编写一个influxdb的未授权访问的漏洞:
from xing.core.BasePlugin import BasePlugin
from xing.utils import http_req
from xing.core import PluginType, SchemeType
class Plugin(BasePlugin):
def __init__(self):
super(Plugin, self).__init__()
self.plugin_type = PluginType.POC
self.vul_name = "Influxdb未授权访问"
self.app_name = 'Influxdb'
self.scheme = [SchemeType.HTTPS, SchemeType.HTTP]
def verify(self, target):
url = target + "/query?q=SHOW%20USERS"
conn = http_req(url)
if b'"results":' in conn.content:
self.logger.success("发现 Influxdb 未授权访问 {}".format(self.target))
return url
else:
return False然后我们直接在本地复现一下,是可以使用的:

接着我们部署到我们的服务器上,注意这里我们将POC同步到arl_web和arl_work两个容器中:
大致流程就是分别进入这两个容器然后添加对应文件下的Poc即可:
cd /opt/ARL-NPoC/xing/plugins/ 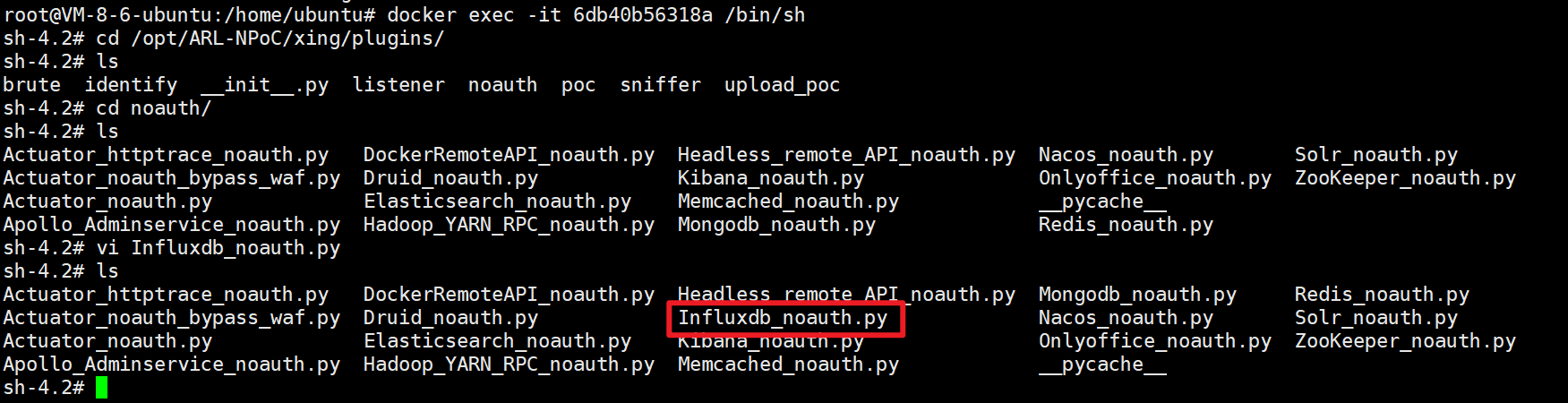
我们更新一下Poc后再前端也可以查看到了:
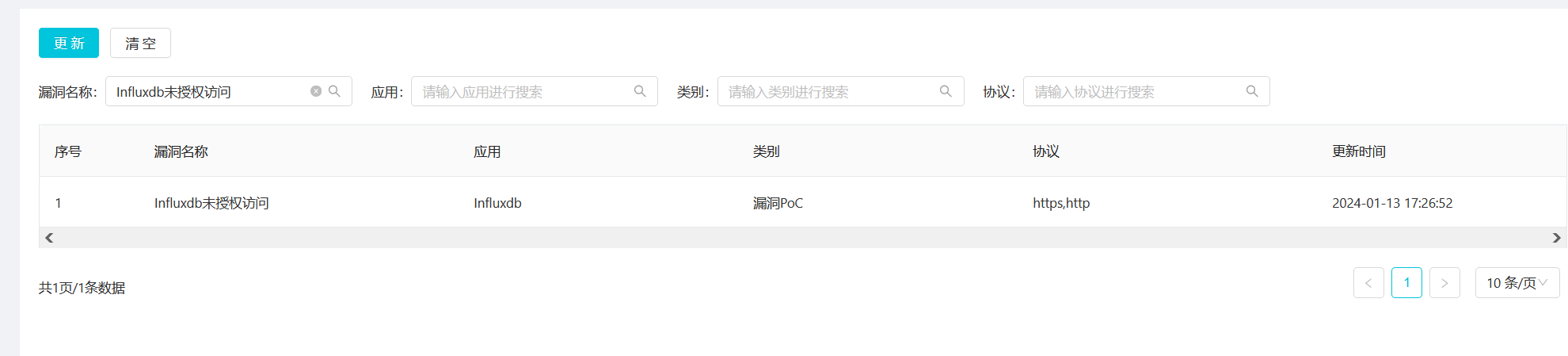
然后经过测试确实可以:
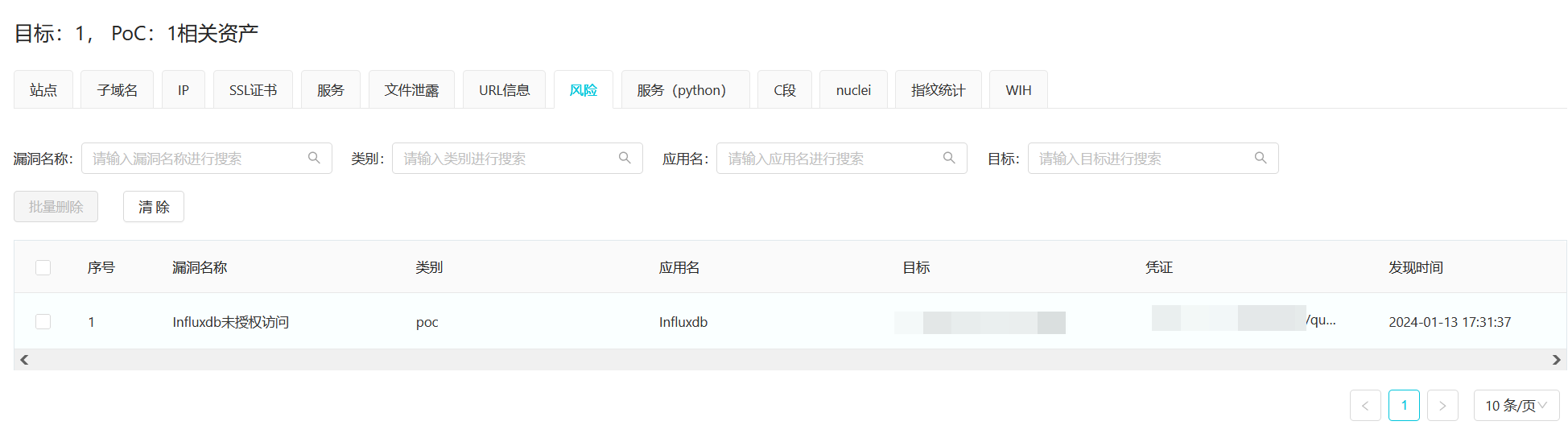
在我的实际渗透测试过程中,ARL给我的信息搜集带来了很大的便利性。是一种全面的信息搜集的有力方式!这篇文章主要是解决一点使用ARL过程中的问题,以及编写自己的Poc的流程。


