-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
渗透测试:比较官方的解释可以查看百度百科,我的理解为渗透测试就是通过一些手段找到网站、APP、网络服务、软件、服务器等网络设备和应用的漏洞,告知管理员有哪些漏洞,应该怎么填补以防止入侵。
下图,为我在学习课程之前了解到的渗透测试流程:
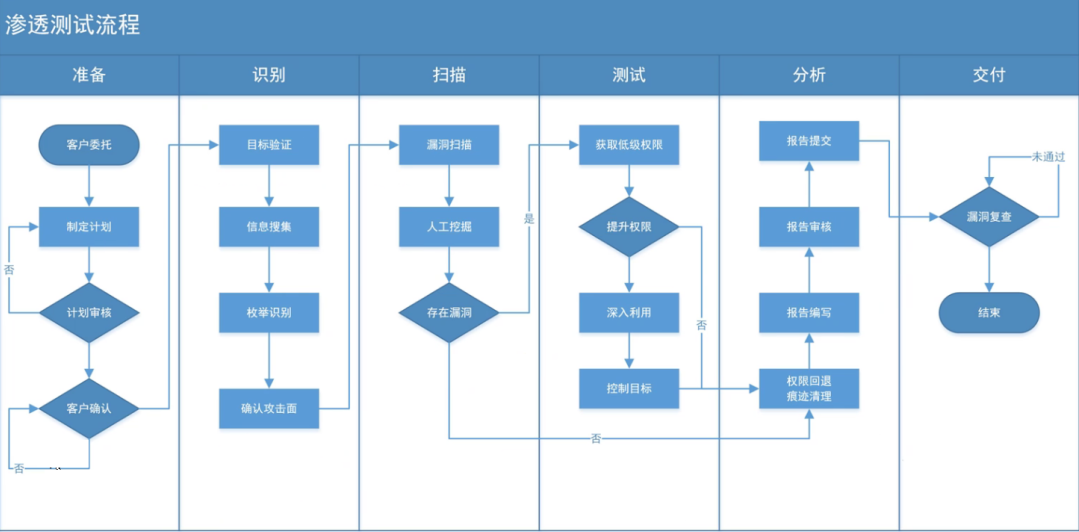
而本次课程中,将渗透测试的流程就更加简化了,总共分为了三个步骤 ——
信息收集阶段:通过已知信息去收集渗透测试目标所有暴露在边界上的系统和信息,从而掌握目标外围所有可能访问到的资产信息
漏洞发现阶段:对收集到的资产进行划分,然后针对不同的目标执行不同的测试方案
报告编写阶段:将之前的所有成果进行汇总,将测试的方法、流程、结果以及漏洞修复建议体现在报告中
其中可以使用脚本自动化完成的步骤为信息收集和漏洞发现,接下来我就来具体介绍一下课程中关于这两个部分的内容
资产范围 → 子域名数据 → 域名对应的IP数据
通常情况下,我们拿到的资产范围都是一些域名列表,类似于下图
所以,我们第一步需要做的工作通常是收集主域名下的子域名与其对应的IP
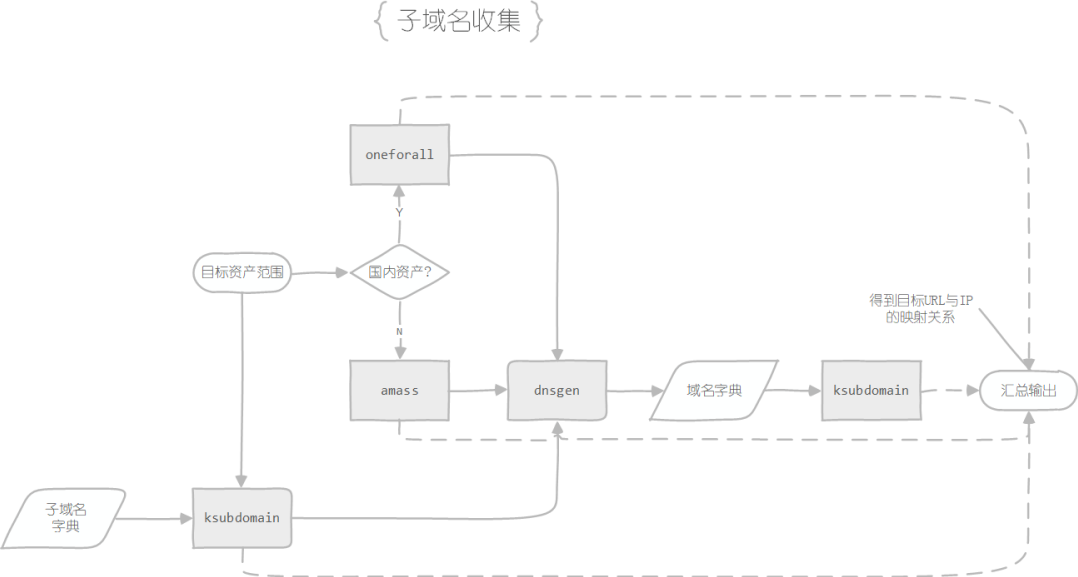
具体步骤如下:
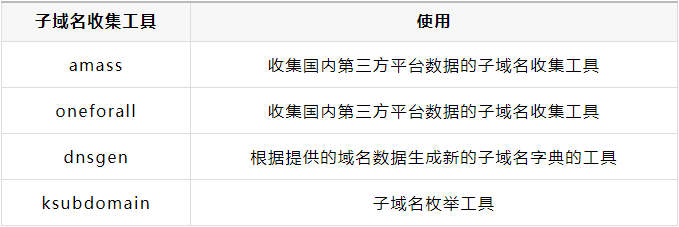
在获取到目标资产范围后,先进行第三方平台的子域名信息收集,使用到的工具有oneforall(国内)和amass(国外)
使用子域名枚举工具ksubdomain的enum模块,利用子域名字典对目标进行子域名枚举,获取相应数据
将前两步收集到的信息去重后传入域名字典生成工具dnsgen生成新的域名字典
使用子域名枚举工具ksubdomain的verify模块,利用新生成的域名字典进行域名枚举,获取相应数据,值得注意的是,verify模块产生的数据不会对泛解析域名进行处理,这里还需要增加一个处理泛解析域名的操作
将所有的得到的数据汇总去重,即可得到一份子域名 + IP的目标数据
子域名与IP的映射关系 → 获取
http://domain:port格式的URL数据
仅仅知道站点域名是不足以确定一个WEB站点的,所以我们还需要获取其WEB服务对应的端口号,最终拿到对应的URL数据
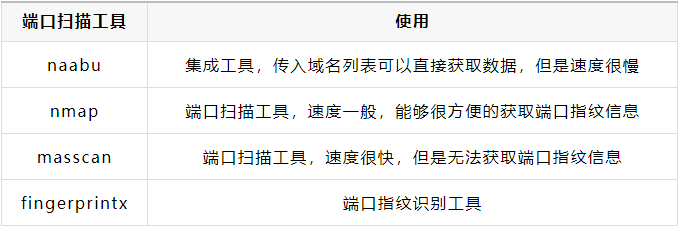
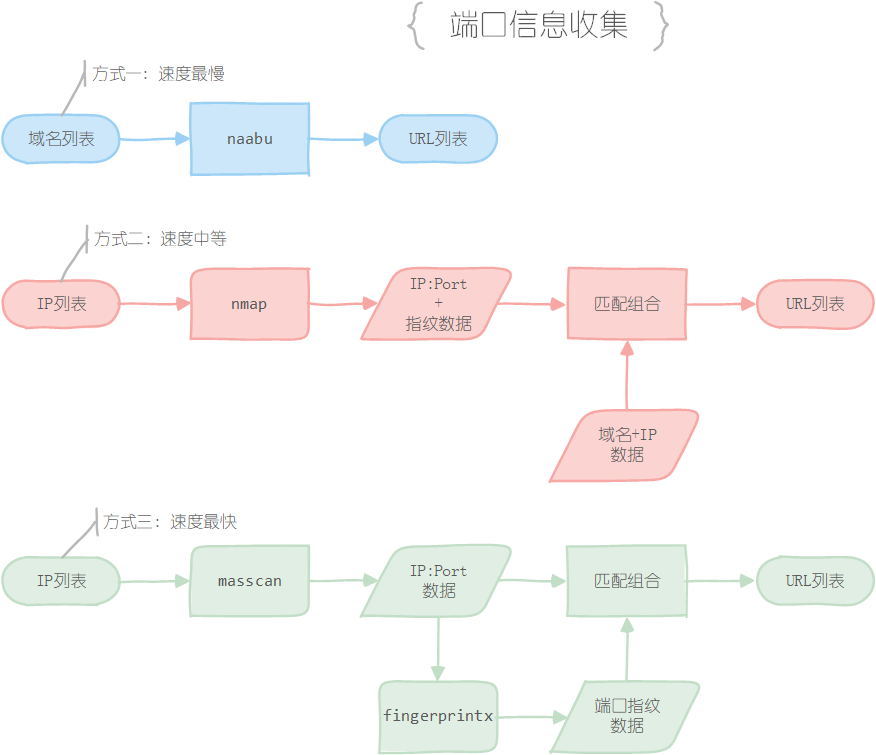
想要通过域名IP数据获取URL数据方式有三种,可以根据个人需求选择对应的方式进行操作:
方式一:直接使用naabu工具进行收集,输入域名列表,输出http://domain:port格式的URL数据,但是速度很慢
方式二:使用Nmap工具的-sV参数对IP列表进行扫描,能够直接获取IP开放的端口和对应的服务信息,通过对服务信息的分类能够获取到开放WEB服务的端口,最后再将端口与域名数据拼接,即可获取http://domain:port格式的URL数据。这种方式不复杂,但是速度也不算快,建议针对单个站点使用
方式三:使用Masscan对IP列表进行扫描,获取其开放的端口,然后使用fingerprintx工具进行端口指纹识别,获取其中的开放WEB服务的端口,最后再将端口与域名数据拼接,即可获取http://domain:port格式的URL数据。这种方式经过测试,速度是方式二的两到三倍
URL数据 → 站点验活 → 站点去重 → 站点指纹识别 + WAF检测 → 目标站点列表
在获取到URL数据之后,我们可以对每个URL进行进一步的验证,排除掉所有失活的站点,再基于站点哈希值进行去重,最后排除掉存在WAF站点,即可获取最终的目标站点列表,然后可以根据需求进行站点指纹识别,为NDay漏洞的利用做准备

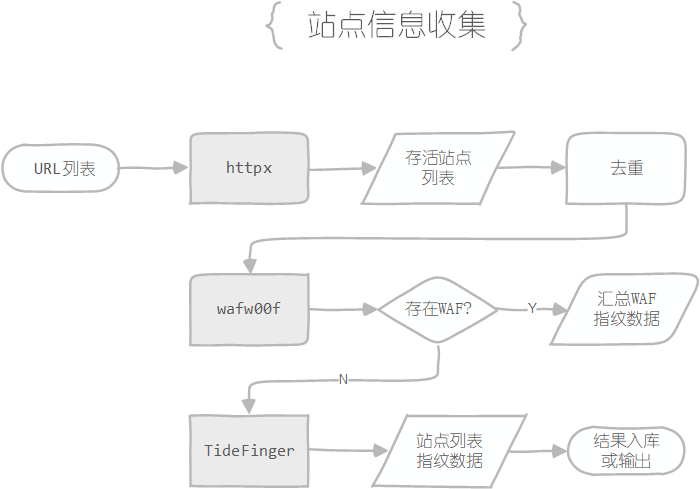
站点信息收集的具体步骤如下 :
使用httpx工具收集所有URL对应站点的哈希值,工具会默认排除失活站点,然后根据哈希值进行去重
使用wafw00f工具对所有存活的站点进行WAF验证,排除掉存在WAF的站点并收集WAF指纹数据入库(若没有WAF指纹识别的需求,仅仅只是进行排除,也可以自己编写WAF判定的脚本),获取经过筛选的站点作为目标站点数据保存下来
如果有需求,可以通过TideFinger工具收集目标站点的站点指纹信息进行入库/存入文件
目标站点列表 → 站点列表
在获取到站点列表之后,需要寻找注入点,即网站的接口(GET、POST传参的参数)

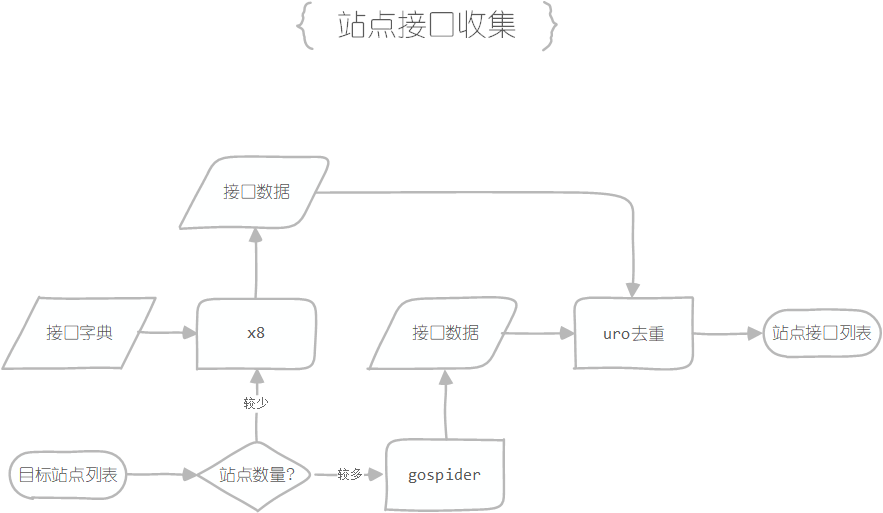
寻找网站接口的方式有二:
方式一:通过接口字典枚举的方式寻找,用到的工具是x8,需要指定对应的参数字典,这个方式效率不高,在站点数量较少的时候可以尝试用
方式二:使用网站爬虫的方式寻找公开的接口信息,用到的工具是gospider,这款爬虫工具为动态爬虫,利用无头浏览器,可以动态加载网页中的 JavaScript 脚本,相比静态爬虫可以获取 POST 请求中的参数,以及可以利用 API 进行数据交互
在收集完网站接口数据之后,可以利用uro工具对数据进行去重,避免重复操作
总结
至此,信息收集步骤已经全部完成,我们再来回顾一下 ——
收集目标站点资产范围,通常为域名范围
子域名收集
WEB端口收集,汇总为URL数据
URL去重、验活以及排除存在WAF的站点
站点指纹识别,信息入库
站点接口数据收集
在之前的信息收集步骤中,我们获取了目标站点的URL数据和接口数据,接下来,就可以利用这些数据进行自动化测试了
在开始前,我们需要了解一下常见的漏洞扫描以及模糊测试工具

其中弱口令枚举工具是对一些非WEB端口可能存在弱口令的应用进行测试;而漏扫工具和Fuzzing工具则是针对WEB服务进行测试
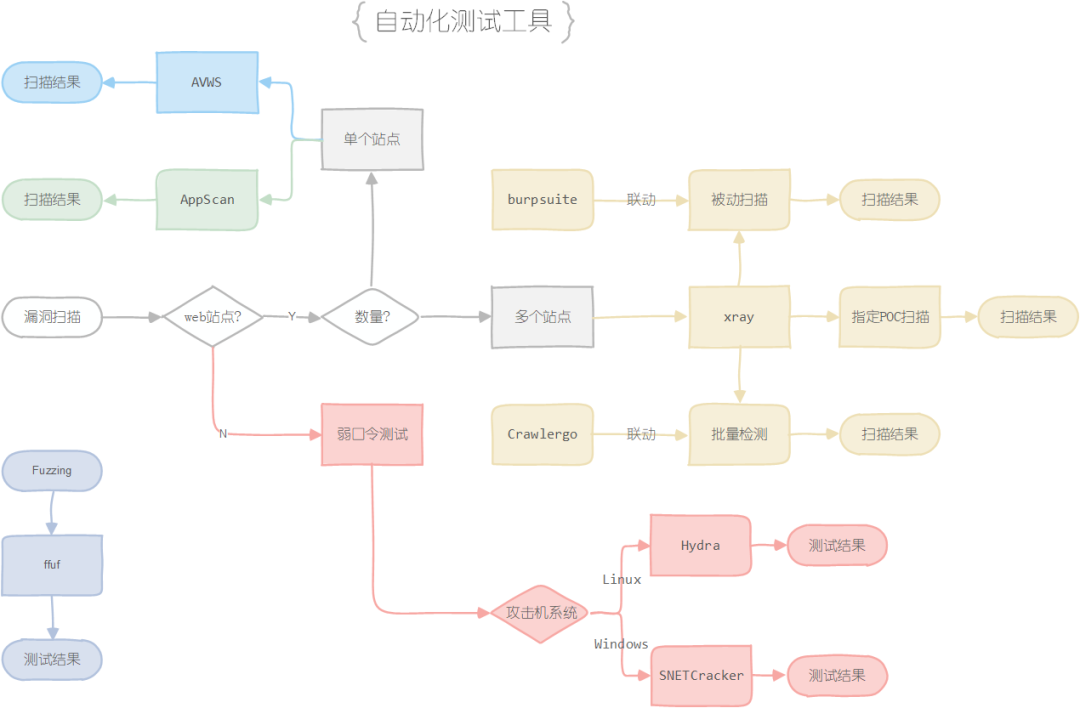
AVWS和AppScan通常是使用针对单个站点进行漏扫的工具,简单易用但是扩展性较差
而这里重点介绍xray工具的使用思路——
被动扫描:在进行手工测试的时候,可以开启xray的被动扫描模式,让它帮助你做一些常见WEB漏洞的探测,而人工的重心可以放在逻辑漏洞的发现上
主动探测:利用xray的主动探测功能对站点接口收集阶段的接口数据进行探测
联动Crawlergo进行探测:先用Crawlergo对站点的URL数据进行爬取,再将流量转发给xray对得到的数据进行探测
这三款工具都能自动生成漏洞扫描报告,报告编写可以将其作为参考资料
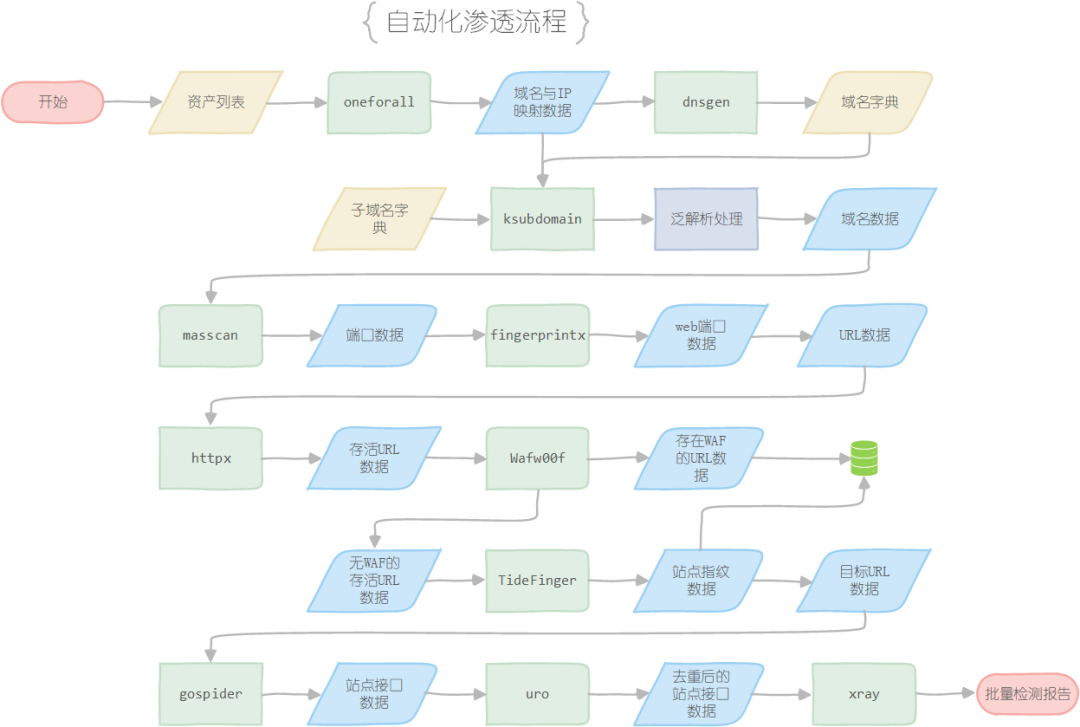
最后的最后,放一张图来总结一下这次渗透实训的整体思路,以上就是我这次参加实训的所有收获。
本文转自信安之路 ,作者:H1kki


