-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
最近一直在考虑如何结合kill chain检测APT攻击。出发点是因为尽管APT是一种特殊、高级攻击手段,但是它还是会具有攻击的common feature,只要可以把握住共同特征,就能进行检测。而kill chain就是个非常好的common feature描述。
在预研期间看到了一些觉得比较好的工作,这里和各位师傅一起分享下。如题所述,这篇文章是介绍如何如kill-chain的角度检测APT攻击的一个方案,其特点解决了三个痛点:1.在于针对大数据量的问题引入Pearson相关检验来减少处理数据量;2,使用基于贝叶斯算法分类的优先级选择方法对训练数据进行选择,从而显著降低训练时间;3.利用层次分析法,对不同的警报进行分类,并确定各参数之间的相关性,最终提高所有攻击数据类的检测率。
kill-chain模型各位师傅应该都比较熟悉了,不过为了方便与后文的APT检测对应起来,我们这里还是简单梳理下。
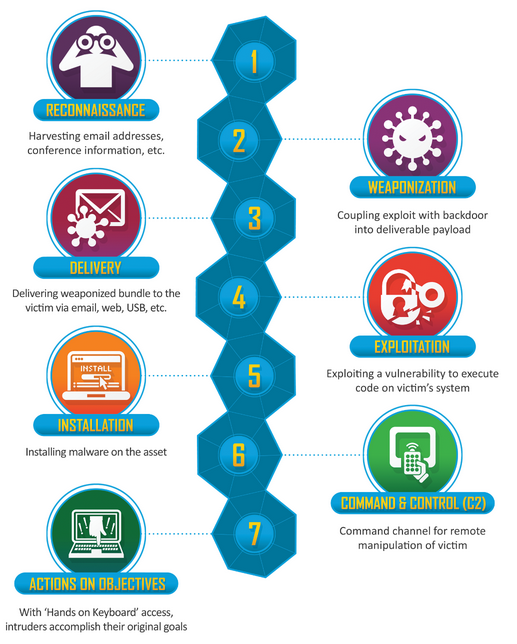
kill-chain模型有7个阶段:(1) Reconnaissance, (2) Weaponization, (3) Deliver, (4) Exploitation, (5) Installation, (6) Command and Control (7) Actions on objectives

这7个连续的步骤为攻击者提供了行动TTP(tactic,technique和procedure)
事实上,kill-chain模型不仅可以给攻击者提供参考,也能给防御者提供指引,从预防、检测、分析每一步骤都有章可循。下面根据个人经验简单回顾一下。
第一阶段侦查的主要目标就是收集目标的信息,这一步说简单也简单,说难也难,相信做渗透的师傅们都深有体会。
第二阶段Weaponization,即武器化,其目标是创建一个可以交付攻击的恶意payload,这里的payload可以分为两种类型:
1.不需要与攻击者通信的payload,比如病毒、蠕虫等
2.需要与攻击者通信的payload,比如带有C&C功能的恶意软件
其实关于这一阶段的产物我们更熟悉的名词应该叫做RAT(remote access Trojan),即远控木马
RAT需要客户端和负责下发命令的服务器。客户端接收实际恶意payload,并被配置为能够与C2服务器通信,服务器位于网络上,由攻击者控制。
比如在Reconnaissance阶段,攻击者注意到电子邮件系统不允许发送和接收exe文件,但允许发送pdf文件。另一方面,攻击者注意到,教授经常通过电子邮件收到并打开学生的PDF文件。因此,攻击者可以创建一个能够与C2服务器通信的RAT文件,并将该RAT文件嵌入到一个伪装为个人简历(比如要读研的前来套磁的学生)的PDF文件中,然后将其以附件的形式发给教授。
payload在上一阶段被开发完成后就需要通过各种途径投递出去,这里可以通过社会工程学的方法欺骗受害者进行交互,或者利用协议、软件的缺陷自动投递。在这一阶段最重要的就是确保投递时的隐蔽性,非交互就能投递的话自然是最好的,可这也是最难的,所以在网上流传很广的那个报价表上'Zero-interaction'的漏洞价格一骑绝尘。
在利用阶段,需要确保其拥有必要的权限以在目标平台上运行,比如投递的是elf文件,则肯定是不能在windows平台运行的;而且payload不能被检测出来,否则kill-chain的链条到这里就断了。
这一步容易和下一步混淆,这一步是利用,下一步才是安装。举个简单的例子,本来是没有权限安装某个app的,但是同个exploition这个阶段实现了提权、逃逸等操作,所以才能保证下一步installation的进行。
这一阶段并不是必须,比如那些可执行文件或者以代码注入实现的攻击。
如果涉及到这个阶段的话,攻击者就需要在deliver阶段将dropper或者downloader放置在目标计算机上。这一步的关键不在于漏洞利用,而是在于持久化,能够在受害者主机上存活下来。
这一阶段是不可或缺的,因为很多攻击活动的目的就是为了窃取信息,那么在本地拿到信息后自然需要通过C2回传,比如典型的Zeus等;此外对于僵尸网络还需要接收客户端的命令以执行恶意操作,比如发动ddos攻击,对于勒索软件需要被下派指令激活以加密本地关键文件
在这一步,根据通信特点也可以分为直接通信和间接通信两类:
在直接通信中,受害主机上的恶意软件包含攻击者控制的服务器ip和控制列表,但是如果这个特定的ip被阻断了,那么攻击者就失去了控制权;
在间接通信中,攻击者是利用合法的中间节点与受害者进行通信的,他可以利用白站进行中转,或者攻陷一些中间节点作为跳板,从而建立通信路径。
这一步其实非常灵活,攻击者可以通过不同的方式进行通信,比如使用邮件、使用http,dns等以及隐蔽信道。
但是这一阶段的活动一定会产生网络流量,因为很多检测工作都是在流量方面开展的。
这是kill-chain模型的最后阶段。攻击活动要么会自主进行或者通过C2信道接收到命令后开始执行。这一阶段的目标主要有三种:窃取信息、勒索软件、破坏系统。
回顾完了kill-chain,我们可以很直观地感受到,这个连续模型,阐述了攻击者是如何一步步实现攻击的,其基于的假设就是攻击者会以顺序、递进和高级的方式对受害者进行渗透,只要任一阶段被阻断,攻击就不会成功。
检测方案非常直观,如下所示
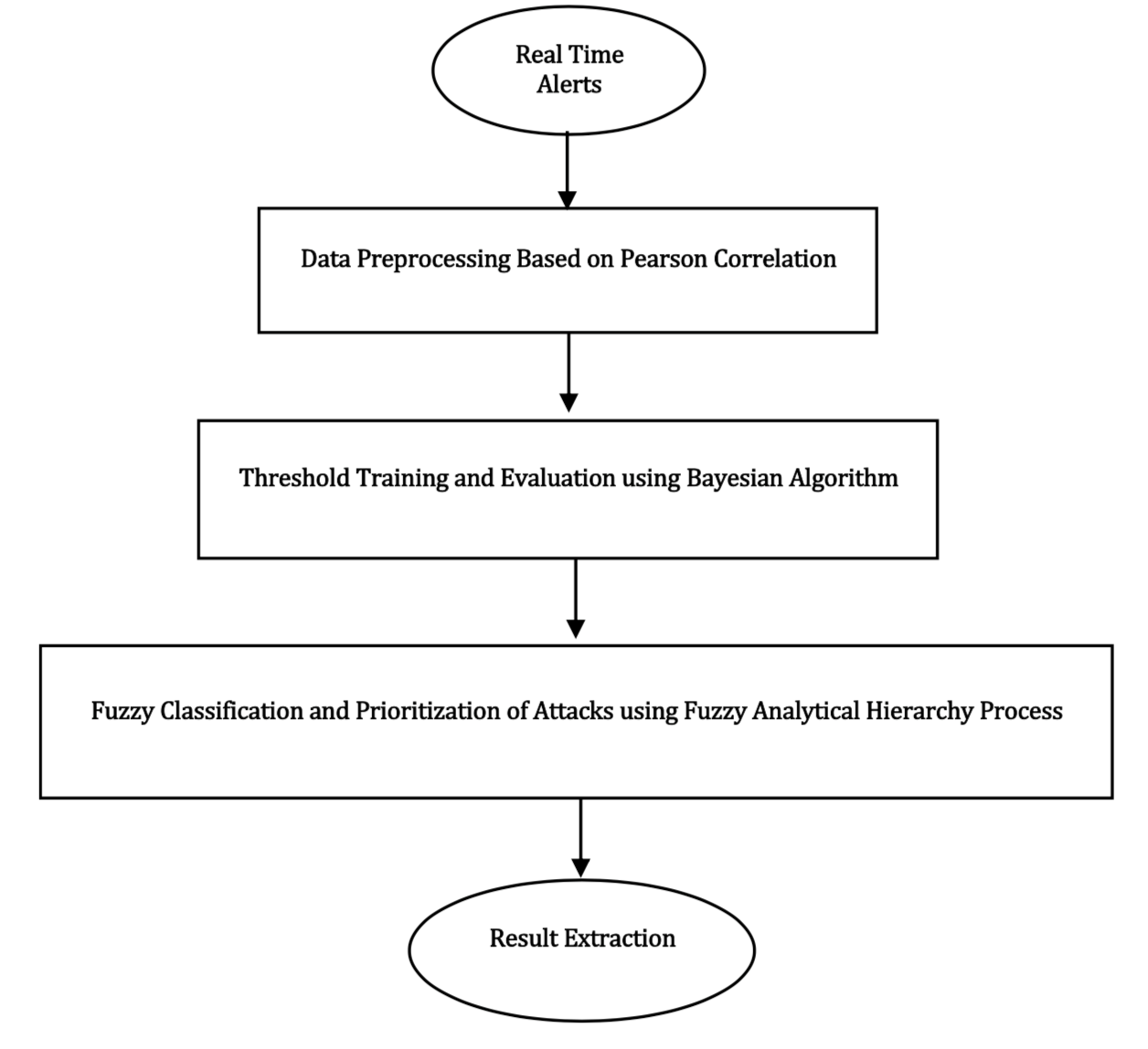
在数据预处理阶段采用Pearson相关检验,利用贝叶斯算法优化训练输入信息。接下来贝叶斯算法根据检测阈值、预测阈值和灰色结果三个组成部分对数据进行分类。然后,将剩余的预处理数据作为实验组件,将其输出作为分析层次过程的输入参数,对攻击进行排序。此时会输出包括一个已知攻击优先级的分类。
检测APT攻击时需要计算几个参数,大部分研究中针对网络攻击的类型和严重程度,已经引入了各种参数来评估和检测网络攻击。但这里需要注意的是,检查许多参数的话可能会增加开销,并最终降低提出的入侵检测解决方案的效率。
所以在这里采用相关系数法减少检测APT攻击时使用的参数数量。
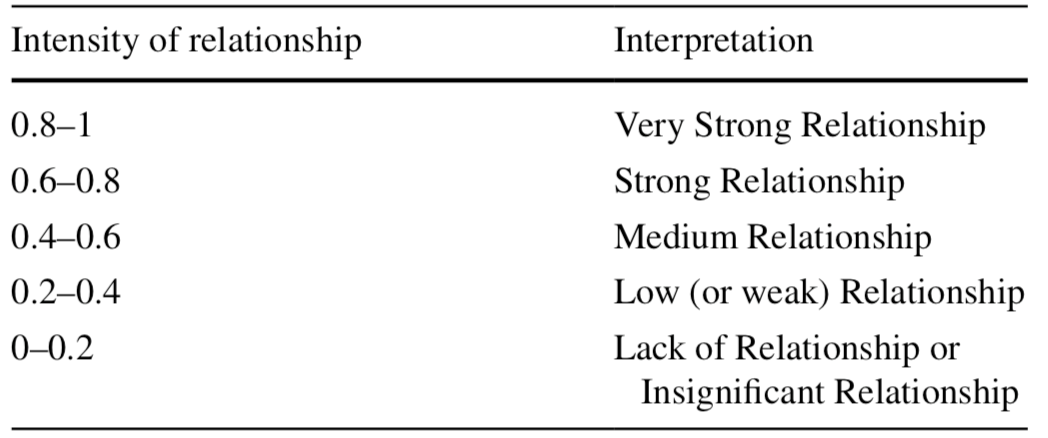
相关系数是确定两个定量变量之间关系类型和程度的统计工具。同时,它也是决定两个变量相关性的因素之一。它表明了关系的强度以及关系的类型。这个系数在−1到1之间。在两个变量之间没有关系的情况下,它等于0。
两个变量之间的相关性可以用各种不同的计算方法来测量。皮尔逊相关系数、斯皮尔曼相关系数和Tau Kendall相关系数是计算变量之间相关关系最常用的方法。在这里我们使用皮尔逊相关系数。一般来说,两个随机变量之间的皮尔逊相关系数等于它们的协方差除以它们的标准差的乘积。对于一个统计总体,相关系数可定义如下
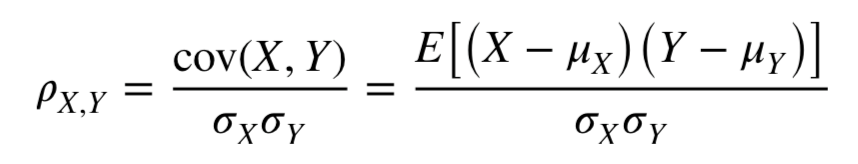
对于有n个数据对的样本的相关系数可以表示如下
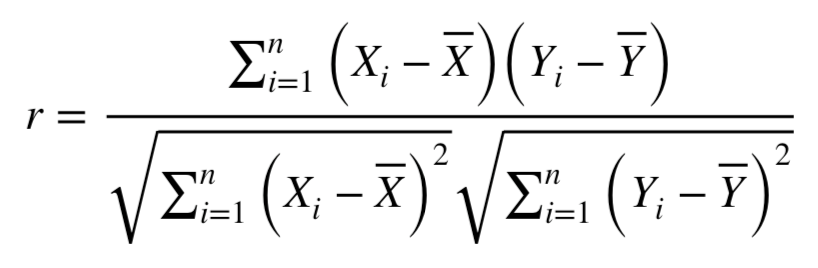
进一步推导为

其中
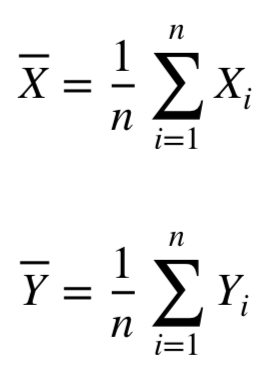

接下来需要评估相关强度,根据给定的应用,提出了各种分类,这些分类用于关联数据以及从大量数据中删除无用数据。
对应的评估可以参考下表
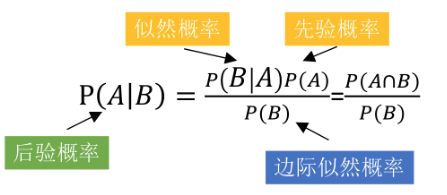
贝叶斯决策理论是一种概率推理方法。假设给定的变量遵循一定的概率分布,这些概率和观察到的数据可以用来做决策。
朴素贝叶斯分类模型(NBC)是基于贝叶斯决策理论的一种基础模型。该分类方法执行简单,分类速度快,准确率高,是机器学习中应用最广泛的分类模型之一。朴素贝叶斯分类基本思想:假设样本属性之间相互独立,对于给定的待分类项,求解在此项出现的情况下其他各个类别出现的概率,哪个最大,就认为待分类项属于那一类别。
比如大家都知道的邮箱内垃圾邮件的筛选即应用朴素贝叶斯算法。我们这里就用它。
其实现主要分成三个阶段
第一阶段,准备工作。根据具体情况确定特征属性,并对每一特征属性进行划分,然后人工对一些待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。唯一需要人工处理的阶段,质量要求较高。
第二阶段,分类器训练阶段(生成分类器)。计算每个类别在训练样本中出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。
第三阶段,应用阶段。使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
理论上来说,朴素贝叶斯分类比其他分类算法的错误率最低。
但是,很难假设实际的网络行为是独立的。因为实际上每个计算机网络都有自己独特的特点,这些特点直接影响入侵检测方法的效果。因此,将一个加权特征分配给简单贝叶斯分类,在朴素贝叶斯分类中,对每个影响这些关系的属性赋予不同的权重时,不同的权值会产生不同的结果,这些权值对入侵检测方法有很大的影响。
在入侵检测系统中,朴素贝叶斯分类的重点实际是用于是确定不同特征权重。
通过公式计算得到的概率被用来确定阈值。通过对阈值进行评估,将结果表示为灰色阈值、预测阈值和检测阈值三种模式。预测模式表示当前入侵信息被检测到的过程。检测模式决定了入侵信息被完全识别和检测的过程。灰色模式表示当前信息无法检测到入侵。
模糊层次分析法(FAHP)及计算过程层次分析法(AHP)是20世纪70年代美国运筹学T.L. Saaty教授提出的一种定性与定量相结合的系统分析方法。
该方法对于量化评价指标,选择最优方案提供了依据,并得到了广泛的应用。然而, AHP存在如下方面的缺陷:检验判断矩阵是否一致非常困难,且检验判断矩阵是否具有一致性的标准CR < 0. 1缺乏科学依据;判断矩阵的一致性与人类思维的一致性有显著差异。
在模糊层次分析中,作因素间的两两比较判断时,如果不用三角模糊数来定量化,而是采用一个因素比另一个因素的重要程度定量表示,则得到模糊判断矩阵。
其抽象结构如下所示
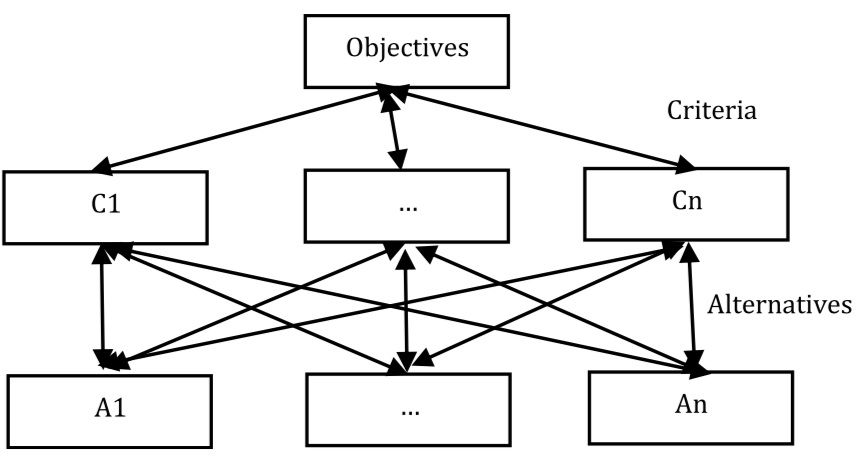
emmm,不好理解的话,我们里去哪里旅游的问题为例,可以把要考虑的因素都放上去进行计算,如下所示
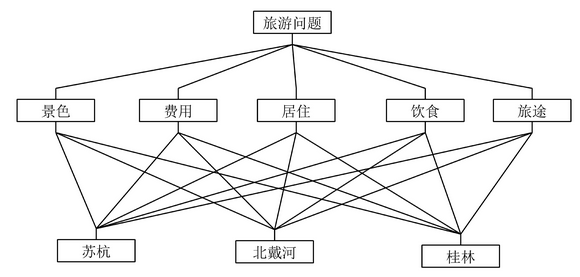
用模糊层次分析法解决问题的一般步骤如下:
模糊层次分析法的基本思想是根据多目标评价问题的性质和总目标,把问题本身按层次进行分解,构成一个由下而上的梯阶层次结构。因此在运用FAHP决策时,大体上可以可分为以下四个步骤。
(1)分析问题,确定系统中各因素之间的因果关系,对决策问题的各种要素建立多级(多层次)递阶结构模型。
(2)对同一层次(等级)的要素以上一级的要素为准则进行两两比较,并根据评定尺度确定其相对重要程度,最后据此建立模糊判断矩阵。
(3)通过一定计算,确定各要素的相对重要度。
(4)通过综合重要度的计算,对所有的替代方案进行优先排序,从而为决策人选择最优方案提供科学的决策依据
在我们提出的方案中,模糊层次分析法是用于对不同的警报进行分类,并确定各参数之间的相关性,从而检测出APT攻击的。
该方法首先会对输入数据进行模糊化处理,数值模糊化可以采用各种隶属函数。隶属度A(x)表示模糊集合A中元素x的隶属度。如果一个元素的隶属度为0,则该元素完全不在该集合中;如果隶属度为1,则该元素完全在该集合中。当隶属度在0到1之间时,表示隶属度是渐进的。这里我们可以使用三角隶属函数对值进行模糊化处理。其公式如下
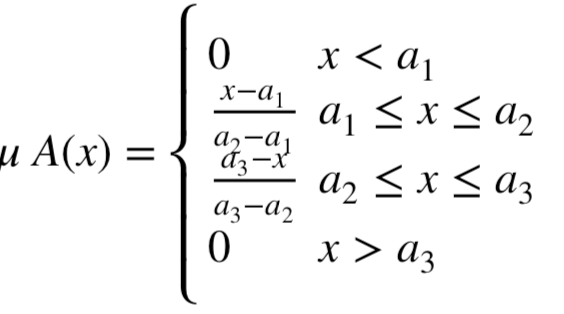
层次分析过程步骤如下:
•AHP建模过程-》创建两两比较决策矩阵-》计算每个选项的标准权重和得分,其最后一步涉及兼容性测试;其中涉及一致性指标(CI)和一致性比(CR)两个参数,当CR小于0.1时,结果才是可接受的,否则就要重新执行
为了检测方案的可行性,这里使用了标准的公开数据集KDD CUP99进行评估
KDD CUP99是非常经典的数据集。该数据集是自1999年以来评估入侵检测系统最常见和标准的数据集,是基于DARPA 98项目记录的数据。该数据集包含由TCPDump软件从网络流量中收集的大约4 GB的原始二进制数据。它还包含大约500万条带有连接向量的记录,每条记录的大小为100字节和41个属性,以及一个包含正常模式或攻击模式的标签。由于该数据集的容量很大,大多数研究都使用了标准数据集中提供的10%的子集。这个数据集包括494,021条记录,包括23种攻击类和2个普通类。
在该数据集中,将数据记录分为拒绝服务(DoS)攻击、获取初始访问(R2L)攻击、提权(U2R)攻击和探测攻击(probing)四大类。在这里,根据kill-chain的特性以及这些攻击对kill-chain模型某些阶段的适应性,以这些攻击为例对APT攻击进行了分析。我们考虑了DoS、R2L、U2R攻击,以及信息收集(“Reconnaissance”)、入侵(“weaponization” 和“Delivery)、部署(““Exploitation” 和 “Installation””)和信息窃取(“Command and Control” 和 “Action on Objectives”)阶段的探测(probing)。为了区分正常流量和攻击流量,KDD99中每个网络通信数据组件用41个属性表示。此外,KDD99中的每个数据组件都被标记为攻击预计或规范预警。数据集中的这23种网络攻击类型都可以用于APT攻击,每一种都属于四种我们设计的攻击类型中的一种。
因为使用了贝叶斯算法和模糊层次分析法相结合的方法,这里通过参数M负责控制这两种算法的收敛(M的值实际上表示Bayesian算法下一步将用于训练的数据点),为了确定M去哪个值更好,这里分别作了实验,效果如下
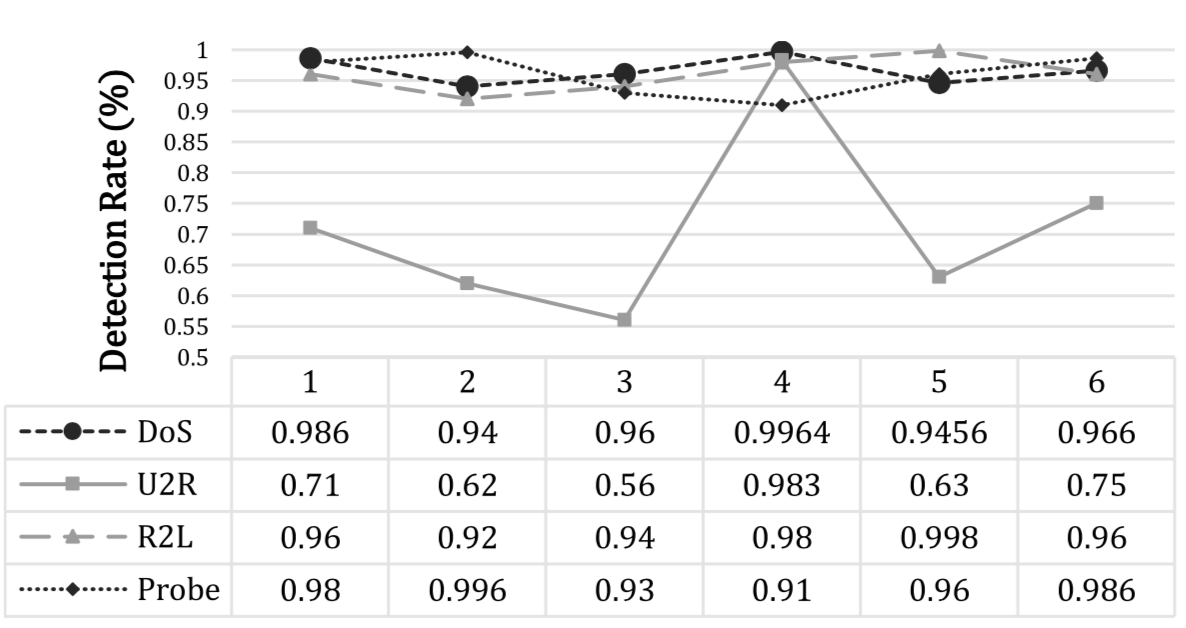
可以看到,M=4时效果是最好的
为了确定所提出的方案的效率更好,这里可以对T2数据集提取混淆矩阵,如下所示。a是基础方案,b是提出的方案.
在接下来的实验中,我们把这里提出的新的思路命名为APT-Dt-KC,然后与参考文献5中提出的DT-EnSVM方法进行对标,从结果可以看到,新的方案全面胜出。
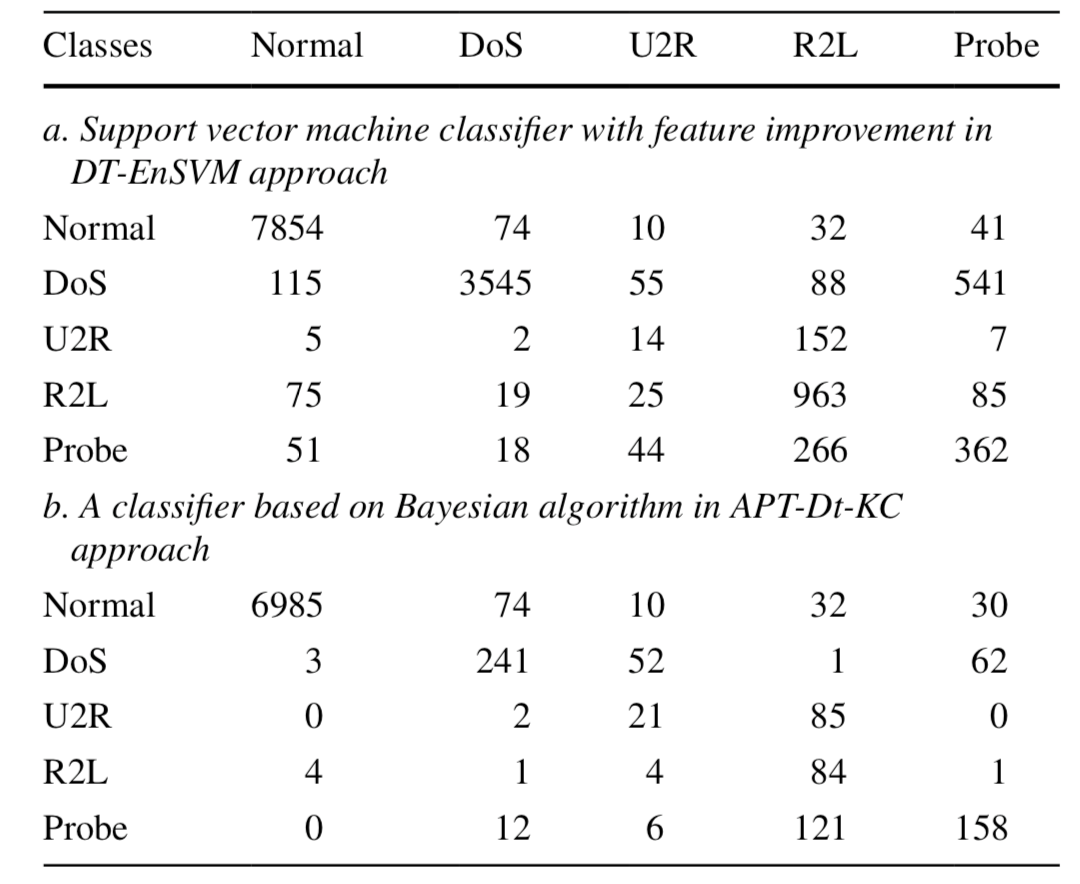
从上表可以看出来,现在的方案混淆矩阵在分类阶段的效率比基础方案要更优。
然后分别比较两个方案在T1数据集和T2数据集上的结果,如下所示,第一个表示是在T1数据集上的结果,第二个表是在T2数据集上的结果
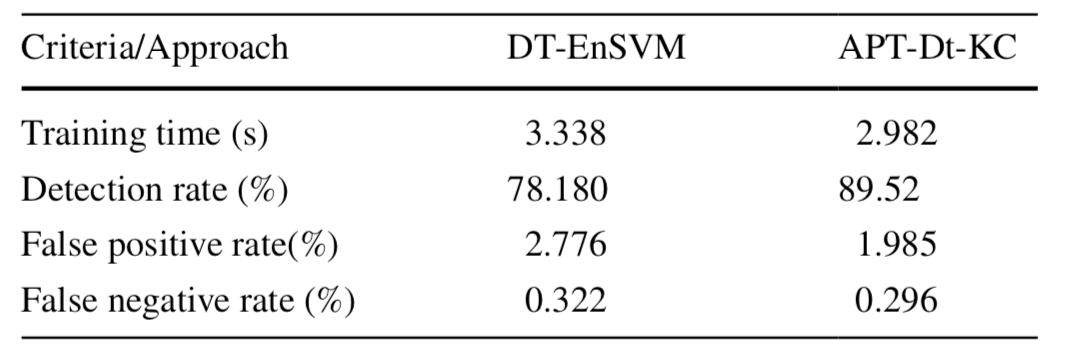
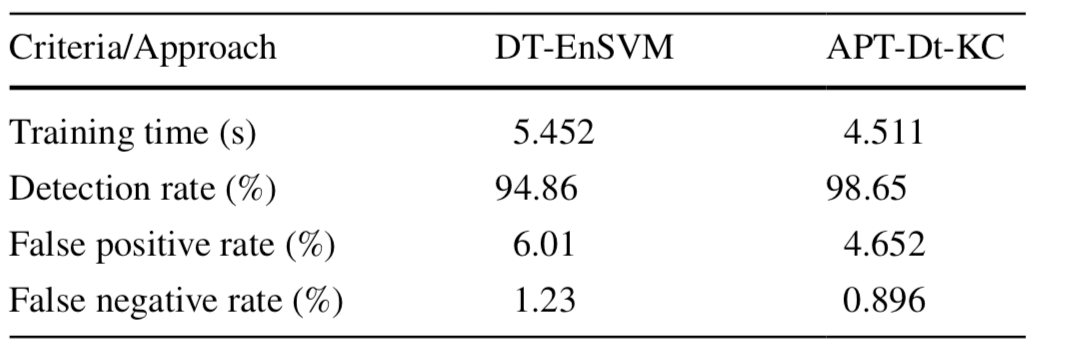
可以看到,现在的方案在检出率、假阳性率和假阴性率方面均要更占优势。而且由于消除了预警的冗余性,其训练时间也更短。
两个方案在两个数据集上的准确率如下
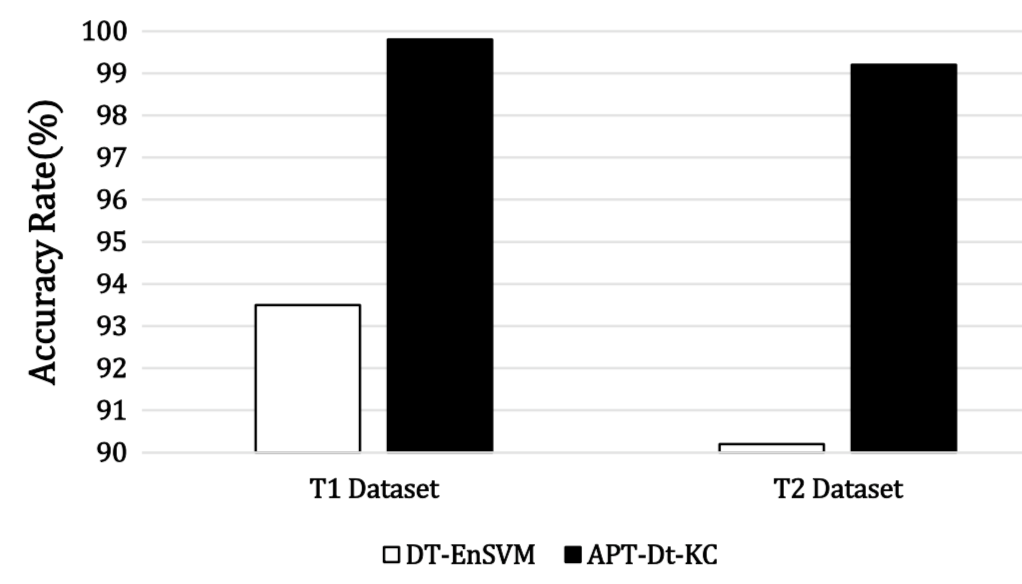
可以看到,现在的方案在准确率上是遥遥领先。
但是这还没有结束,对攻击进行分类处理后,需要确定攻击的级别和优先级。
由于现在的方法采用了AHP算法来考虑攻击的级别,因此可以对不同的攻击进行排序。因此,可以对所有攻击进行分类、排序,并根据最可能发生的情况进行评估。T1数据集在攻击检测阶段的实验结果如下所示。

可以看到其假阳性率和假阴性率均小于基础方法。
T1数据集中两个方案的平均检测率值如下所示
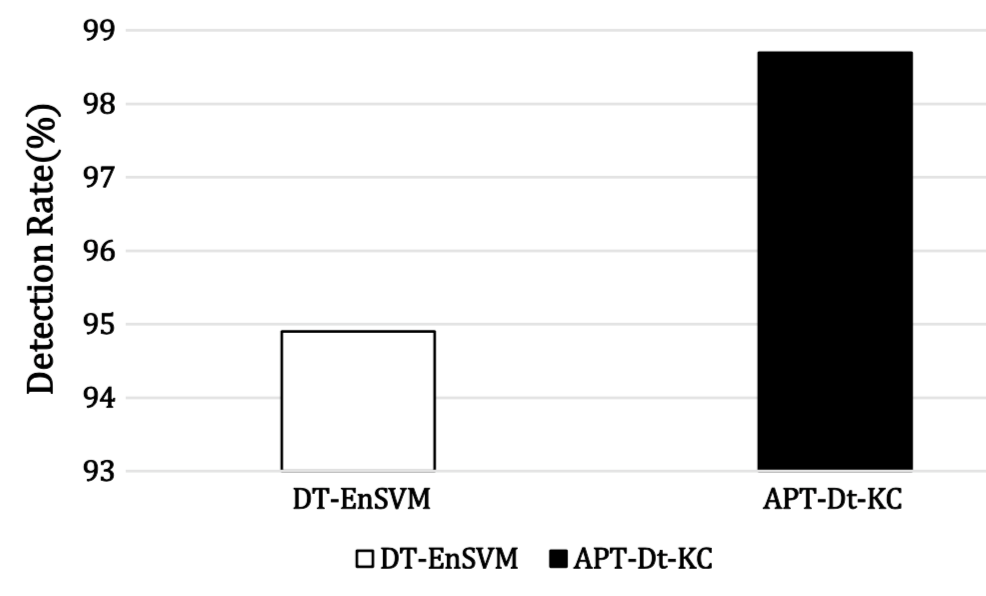
从表中可以看出,现在的方案在最终检测率上也是优于基础方法的。所以我们现在可以肯定地说,整个过程中我们提出的新方案有较好的检测效果。
1.Panahnejad M, Mirabi M. APT-Dt-KC: advanced persistent threat detection based on kill-chain model[J]. The Journal of Supercomputing, 2022: 1-34.
2.https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html
4.Setiawan B, Djanali S, Ahmad T, et al. Assessing centroid-based classification models for intrusion detection system using composite indicators[J]. Procedia Computer Science, 2019, 161: 665-676.
5.Gu J, Wang L, Wang H, et al. A novel approach to intrusion detection using SVM ensemble with feature augmentation[J]. Computers & Security, 2019, 86: 53-62.


