-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
我们一直都在说,密码学是网络空间安全领域的唯一理论支撑,大家都认为密码学是安全的压舱石。
密码学对安全的关键意义毋庸讳言,安全领域非密码学的师傅们而言,对于密码学的认识可能限于打CTF时接触的基础的凯撒密码、栅栏密码到涉及分析的padding oracle attack等,再到要读最新的论文手动编程才能求解的一些问题。
大家对密码学的安全性问题了解并不足够,本系列文章核心来自我们在学习相关文献时的学习记录,整理成文希望能够提升大家对”压舱石“安全性的认识。
具体而言,在本篇文章中,我们会介绍密码学的安全性的定义、如何保证安全性;之后会介绍古典密码及其本质的缺陷,然后引出一次一密;接着会定义攻击模型及安全目标,并通过分析引出随机性的重要性,为了便于理解,在文中会时刻举例说明,同时给出实际中由于对密码学安全性理解不足而发生过的安全事故。
密码学中的安全性与计算机中的安全性是存在区别的。
计算机安全,我们以软件安全为例,其目标是防止攻击者利用程序代码触发漏洞,而密码学安全的目标是使定义明确的问题无法求解。对于软件安全而言,一个软件要么是安全的,要么是不安全的,但是对于密码领域的程序而言,安全与否并不是绝对的,我们可以计算出破解加密算法所需的工作量,即量化其安全性,但是却不能绝对称其为安全。
密码学中的安全性可以分为两种:理论安全性与计算安全性。当攻击者拥有无限时间和资源还是不能破译密码时,称其为理论安全,也叫做无条件安全,下文会介绍的一次一密便是典型;而如果一个密码算法在给定时间和资源内无法被攻破,则称其为计算安全的,这与攻击者的能力、目标等条件密切相关,在下文我们会根据不同的条件建立不同的攻击模型与安全目标等。
举个例子,设一个密码算法E的密钥K是128比特,加密过程为C=E(K,P),已知一个明文-密文对(P,C),但是不知道K。
求K,这个问题不是理论安全的,因为我们可以穷举2^128种可能;但是这个问题是计算安全的,因为即使一秒钟可以穷举1000亿个K,要穷举
2^128个K要花费超过100 000 000 000 000 000 年的时间,在实践中是安全的。
我们这里可以给出形式化的定义,设对于一个密码方案,攻击者最多能执行t个操作,攻击成功概率不高于ε,则该方案是(t,ε)-安全的,此时给出的是破解密码算法的难度的下限。注意,这意味着,没有攻击者能够在执行小于t次操作得情况下,获得概率为ε的成功率,但是这并不是说明攻击者执行t次就恰好可以成功,也不会说明需要具体多少次才能成功,所以t实际上是攻击算法所需的操作量的下界。
还是以攻击128比特密钥的对称密码算法为例,理想情况下,此密码对于1到2^128之间的任何t值都是
(t,2/2^12)-安全的,最好的攻击就是暴力破解。我们可以计算以下三种可能的攻击的成功概率:
1.t=1,说明攻击者尝试了一个密钥,并以ε=1/2^128的概率成功
2.t=2^128,说明攻击者尝试了所有密钥,其中一定有一个是成功的,所以成功概率ε=1
3.t=2^64,此时的成功概率ε=
2^-64,也就是说,攻击者尝试所有密钥的一小部分时,成功概率与尝试的密钥数量成正比。
从这个例子我们可以看出,对于1到2^n比特之间的任意t,一个n比特密钥的密码至多是
(t,t/2^n)-安全的,因为无论密码多强大,暴力破解总是可以成功的,实际中的关键就是在于能够抵抗暴力攻击多久。
我们可以对(t,ε)-安全进一步简化。我们说当攻击成功至少需要t次操作时,称其为t-安全,这里我们实际上假设ε是接近1的概率,通过比特表示安全性,”n比特安全“说明攻破它需要2^n次操作。
而直到操作次数后,我们就可以通过取其对数确定其安全强度。假设需要1000000次操作,则其安全强度为log2 1000000=20比特。
虽然比特安全性在比较不同密码的安全强度时很有用,但是其没有提供足够的关于攻击成本的信息,仅仅通过比特安全性并不能说明什么,比如两个密码都有128比特密钥和128比特安全性,但是第一个密码比第二个快100倍。那么实际上对第二个密码进行暴力破解2^128次时,可以对第一个密码做
100x2^128次操作了,如果我们以第一个快密码为标准,那么破解慢密码需要
2^134.64次操作。
那么,这能够说明第二个密码比第一个密码安全吗?当然不行,所以我们还需要考虑其他因素。
设有两个攻击,每个攻击都需要2^56次操作,第一种攻击只能串行,第二种攻击可以并行。假设我们有
2^16=65536个处理器,那么可以将并行工作的负载分成65536个独立任务,每个任务只需要执行
2^40次操作即可。
也就是说,即使并行攻击和顺序攻击执行相同数量的操作,但是并行攻击比顺序攻击快65536倍。
这实际上和攻击所用的空间成本有关,即攻击需要多次内存查找、内存访问速度、访问数据大小等,这些对时间的影响非常关键。例如在当前的CPU上,从寄存器读数据需要1个周期,从CPU缓存读数据需要20个周期,从DRAM读数据需要100个周期。
这一般被称作攻击的离线阶段,这些操作只需要执行一次,在后面的攻击中就可以重复使用。比如彩虹表破解hash就是这一类,虽然在计算彩虹表进行预计算时会花费大量时间,但是在实际攻击过程中很快就可以实施。
攻击目标数量越多,攻击面就越大,攻击者就可以拿到更多关于密钥的信息。举个例子,设目标为n比特的密钥,需要2^n次尝试才能找到正确的密钥,但如果攻击目标为多个n比特密钥,即对于单个明文P,攻击者有M个不同的密文,其分别用M个n比特密钥加密得到。如果攻击者要破解的是M个密钥中的每一个,那么还是需要
2^n次操作,但是如果只需要破解M个中的一个,那么只需要
2^n/M次操作。
也就是说,攻击成本随着目标数量增加而降低。
要评估某密码算法的安全性,我们一般会通过数学证明得到。
在密码学中其被称为可证明安全性,它可以证明某个密码方案至少和解决另一个已知的困难问题是同等困难的,只要困难问题仍然存在,那么方案就是安全的,这种证明方式被称为规约,其来自复杂性理论。
安全性证明根据其所使用的困难问题的类型,可以分为两种:与数学问题相关、与密码问题相关。
破解这类方案至少与解决一些数学难题一样困难。
密码学中一个著名的数学难题就是大数分解,RSA正是依赖于它。RSA通过计算C=p^e mond n来加密明文p,其中,e和大数n=pq是公钥。
通过P=c^d mond n解密,其中d是和e、n有关的私钥。
如果我们可以分解n,那么就可以从公钥中恢复私钥来破解RSA;如果有私钥,就可以分解n。
换句话说,恢复RSA私钥和分解大数n是等价的困难问题,这就是我们所说的归约。
这类方案是与另一个密码方案比较,并证明只有破解第一个密码方案时,才能破解第二个密码方案。对称密码的安全性证明常用这种方式。
不过可证明安全性并不适用于所有类型的算法,有一些密码算法并没有被证明是安全的,如AES,AES不能规约到一些众所周知的难题,既不与数学问题相关,也不与密码问题相关,而我们之所以还用AES,是因为许多专家尝试破解它但是失败了。此时的安全性证明,我们成为启发式的:密码分析人员分析多轮后,密码算法的安全冗余还是很高,我们就相信它是安全的。
我们已经说了安全性证明非常重要,但是密码学大佬们在进行安全性证明时仍然有可能犯错,对于OAEP的证明就是一个典型例子。OAEP是一种使用RSA实现安全加密的方法,在许多应用程序中使用,OAEP给出的安全性证明中声称其抵抗选择密文攻击的有效期为7年,但是后来大家研究发现证明是错误的,给出的结论也是错误的。之后给出了新的证明,结论是OAEP对选择密文攻击是安全的。
古典密码是计算机发明之前的密码,算法作用在字母上而不是比特位上。古典密码中最经典的就是凯撒密码和维吉尼亚密码,二者的基础知识背景这里不再介绍。
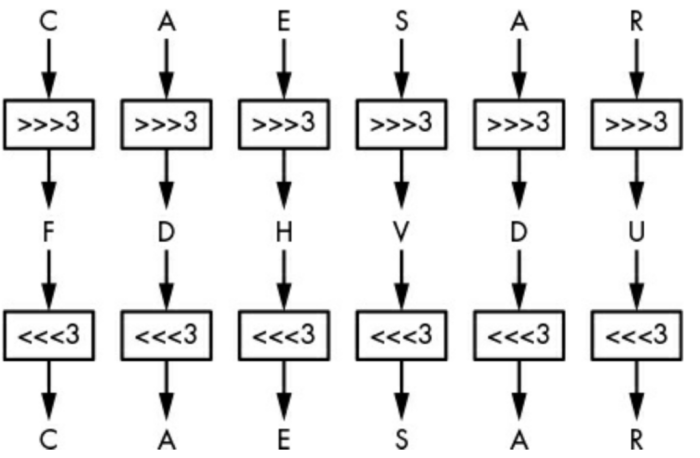
凯撒密码容易被破解,只需要把密文往前移动3位即可得到响应的明文。这种方式安全程度非常低,在古罗马时期经常被使用,不过实际上,前些年意大利警方还通过破译一种凯撒密码的变种抓到了黑手党头目。要增强凯撒密码的安全性,可以改变移位的位数,不过即使这么做了,攻击者最多尝试25次也就可以解密了。
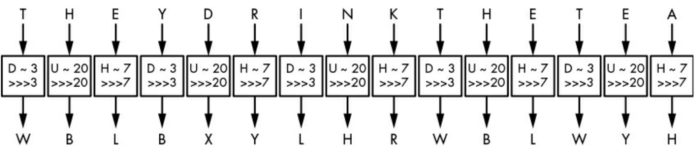
维吉尼亚密码虽然比凯撒密码安全了很多,但还是容易被攻破。
举个例子,明文“THEY DRINK THE TEA"通过密钥”DUH“加密后的密文为”WBLBXYLHRWBLWYH“
第一步找出密钥的长度。我们注意到密文中WBL出现了2次,间隔9个字母,这意味着相同的3个字母被用同样的移位模式加密,所以密钥长度要么是9,要么能够整除9.而在英语中,THE是最常出现的3个字母的组合,所以我们可以认为这个重复的3个字母为THE,那么可能的密钥就是DUH.
第二步使用频率分析法找出字母分布的不均匀性。在英语中E是最常见的字母,所以如果密文中X出现次数最多,那么X对应的明文很可能就是E
通过上面对两种古典密码的简单分析,我们已经知道密码的工作原理主要就是置换和模式。
置换是指能够变换一个对象的函数,且对每个对象都有唯一的逆(如凯撒密码中的3字母移位),而模式则是通过置换处理任意长度的消息的算法(如凯撒密码中的模式就是对每个字母施加相同的置换,而维吉尼亚密码中则是对不同位置的字幕施加不同的置换)
并不是任意置换都是安全的,为了保证安全,置换需要满足:密钥确定置换,只要密钥保密,则置换保密。不同的密钥确定不同的置换。置换应当看起来随机,经过置换的密文应该没有显著的特征或者可识别的模式。
如果满足以上条件,则称这种置换为安全置换,但是这仅是建立安全密码的必要不充分条件,因为其还和模式相关。
在说明操作模式为什么也是建立安全密码的必要条件之前,我们举个例子。
假设我们现在已经有一种安全的置换:A->X,B->M,N->L
那么对于香蕉的英文BANANA则有密文:MXLXLX
我们注意到,仅仅对明文中的所有字母施加相同的置换,在密文中会表现出一种重复的模式,攻击者分析这种模式,即使不能获得完整的信息,但是也能获得一部分信息,比如在这个例子的密文中我们看到在字母的第2,4,6位出现相同的字母,在3,5位出现了相同的字母,如果攻击者知道密文对应的是一种水果,那么攻击者很容易推测出这是BANANA,而不是ORANGE等其他水果。
从这个例子可以看出模式的重要性,模式通过对相同的字母施加不同的置换从而降低了明文中重复字母在密文中表现出的特征的风险。以维吉尼亚密码为例,如果密钥长度为N,那么就有N种不同的置换被施加在连续长度为N的字母串上,不过如果N并非足够长,我们就可以通过频率分析对其进行攻击。所以,如果维吉尼亚密码并应用于加密与密钥长度相同的明文,则频率分析就失效了。
我们回过头来在看古典密码,它注定是不安全的,以我们现在的计算能力分分钟就能攻破它。我们知道,为了确定安全,置换应该看起来是随机的,最好的方法就是从所有置换的集合中随机选择每个置换。实际上可以选择的置换有很多,对于字母表,有26!,约等于2^88种置换,但是古典密码却只能使用其中的一小部分。
此外,置换不仅仅可以通过字母移位进行,还可以使用其他操作如乘法、加法等,这便是现代密码了,比如给定128比特密钥,然后进行一定比特位的操作来加密单个字母。
古典密码是绝对不安全的,那么有没有绝对安全的密码呢?
有的,那便是我们这里有介绍的一次一密。
一次一密有绝对的保密性,即使攻击者有无限的计算能力,也无法了解除明文长度以外的任何信息。
设明文为P,密钥为K,其长度与P相等,密文为C,则一次一密的加密过程为:
![]()
这个符号是异或运算符
解密则是
![]()
一次一密的关键在于密钥K只能使用一次。如果使用两次,设分别将明文P1,P2加密为C1,C2,则攻击者通过如下运算
![]()
可以得到P1,P2的异或结果,从而导致信息泄露(当攻击者这知道一条明文时,就可以通过上式结果推出另一条明文)
一次一密的不便之处在于密钥长度需要和明文一样,除了这个缺点外,是非常完美的。香农在上世纪40年代的时候就已经证明了其安全性。
香农指出,要实现完美的保密,一次一密的密钥必须至少与明文一样长,这样攻击者就无法在给定密文的情况下排除任何可能的明文。
这是非常直观的,如果K是随机的,那么C也是随机的,因为随机字符串与任何固定字符串异或得到的结果也是随机的。随机比特串第一位为0的概率为1/2,一个随机比特与另一比特异或的结果为0的概率为1/2,在任意长度的比特串上这一点都成立。换句话说,对于不知道K的攻击者而言,即使其拥有的时间和算力是无限的,但是对他而言C依然是随机的。
假设C长度为128比特,那么有2^128种可能的密文,对于攻击者而言,
就有2^128种可能的明文。如果密钥长度小于128,即可能的密钥少于
2^128种,那么攻击者可以排除某些明文。比如密钥为64比特,那么攻击者可以确定
2^64种可能的明文,这就排除了大多数的128位比特串。
此时攻击者可能不知道明文是什么,但是其知道明文不是什么,从而破坏了完美保密性。
现在我们已经知道,古典密码不安全,一次一密不实用,那么怎么设计安全和实用兼顾的密码呢?
如果一个密码体制是安全的,必须要定义好对应的攻击模型和安全性目标。攻击模型是关于攻击者可能与密码算法如何交互以及攻击者能力的一系列假设。在进一步分析之前,我们要先了解Kerckhoff原则,其指出,密码的安全性应仅取决于密钥的保密性,而不应取决于密码算法的保密性。
如果攻击者只能看到密码模型的输入和输出,则称其为黑盒模型。黑盒模型中依据从最弱到最强的顺序列举如下:
唯密文攻击(ciphertext-only attackers,COA):仅知道密文,但不知道相关的明文,也不知道有哪些可以选择的明文。此时攻击者是完全被动的,无法执行加密或解密操作
已经明文攻击(known-plaintext attackes,KPA):知道密文以及其对应的明文。此时攻击者也是被动的,不过它可以获得一系列明文-密文对,其中明文是随机选择的。
选择明文攻击(chosen-plaintext attacks,CPA):可以对选定的明文进行加密并得到对应的密文。此时的攻击者是主动的
选择密文攻击(chosen-ciphertext attackers,CCA):可以进行加密和解密。注意,这个模型只是表示攻击者可以介入加密和查看明文的情况,其解密的内容并不一定足以攻破系统。
灰盒模型中,攻击者可以访问密码的实现,比如对于智能卡、嵌入式系统等,攻击者对其拥有物理访问权限,从而可以篡改算法的内部结构。这类模型中最典型的一类就是侧信道攻击。
侧信道攻击依赖于密码实现的信息源,攻击者观察密码实施时的模型特征,比如对于软件而言,可以观察其执行时间、错误消息、返回值、分支等,对于硬件而言,可以观察其功耗、电磁辐射等。
侵入式攻击也属于灰盒模型,其可以通过激光故障注入等方法改变芯片的行为。
我们之前一直都没有明确定义密码的安全目标,只是笼统地说,能让攻击者对密码一无所示的就是好方法,实际上这是远远不够的。实际上,已经有两个常用的安全目标了。
1.不可区分性(indistinguishability,IND):密文应与随机字符串没有区别。关于这一点,可以通过一个game说明。
设攻击者选定两个明文,收到两者的密文之一,攻击者无法分辨出这是哪个明文对应的密文
2.不可展性(non-malleability,NM):给定密文C1,应该不可能创建另一个密文C2,使其对应的明文P2以有意义的方式与P1相关
上述的安全目标仅在于具体的攻击模型结合时才有用,一般我们会写作GOAL-MODEL,如IND-CPA,表示的是针对选择明文攻击者的不可区分性。
以IND-CPA为例,这是最重要的安全概念之一,这也称为语义安全,只要密钥保密,密文就不会泄露任何有关明文的信息,当对同一明文加密两次时,加密系统会返回不同的密文。
IND-CPA的关键是随机化,我们还是以IND game为例。设攻击者选择两个明文P1,P2并接受两个明文之一对应的密文但是不知道它对应的是哪一个明文。在CPA模型中,攻击者可以执行加密以获得大C1=E(K,P1),C2=E(K,P2),如果加密不是随机的,那么攻击者查询Ci是否等于C1或C2就可以确定对哪个明文加密,从而赢得game。
实现IND-CPA最简单的方式就是使用确定性随机比特发生器(deterministic random generator,DRBG),它可以返回给定的某些秘密值的随机比特:
E(K,R,P)=(DBRG(K||R)异或P,R)
上式中的R是每次加密随机选择的字符串,并与密钥K一起提供给DRBG,如果其生成的是真随机比特串,那么该密码的就是IND-CPA安全的。
这里我们只是简单分析了IND-CPA,这种GOAL-MODEL组合还有很多,比如NM-CPA,NM-CCA,IND-CPA,IND-CCA等,他们之间的一些关系是很明显的:IND-CCA蕴含着IND-CPA,NM-CCA蕴含着NM-CPA,因为CPA攻击者可以做的事情CCA攻击者也可以做。
以上我们都还是考虑了对称密码,对于非对称密码而言,由于任何攻击者都可以使用公钥加密,所以模型默认都是CPA的
尽管我们已经介绍了相关的密码学概念,但是在实际中如果没有选择适当的密码算法、模型等,还是会造成严重的危害。
在GSM时代,手机通信的加密使用了A5/1的算法,通过建立查找表便可以对其进行攻击。在参考连接6中,可以看到详细的情况。
即使密码使用者学习过安全模型,但还是有可能使用错误模型。很多通信协议确实使用了在CPA或CCA中安全的算法,但是实际中有些攻击是不需要涉及CPA中的加密查询或CCA中的解密查询的,比如对于Padding oracle attack而言,只需要进行有效性查询即可,在这种攻击方案下,只有密文对应的明文有适当的填充时,密文才有效,如果填充不正确,解密就会失败,攻击者可以通过观察解密是否失败进行攻击。
这种攻击方案,打CTF的师傅们应该很熟悉了,这里也不再进一步说明,有兴趣的话也可以参考《白帽子讲web安全》中的相关章节。
我们已经知道,在密码系统中,需要随机性来保证安全。可以说,其中的关键就在于随机比特的生成,其依赖于熵源以及从熵源产生随机比特的算法。
熵源由随机数发生器(RNG)提供,算法由伪随机数发生器(PRNG)提供。
RNG的作用是利用模拟世界中的熵在数字系统中生成不可预测的比特,比如从温度、噪声、静电测量中采样出比特信息,也可以从传感器,IO,系统日志等提取正在运行的OS中的熵。而PRNG的作用则是从一些真正随机的比特生成许多人为的随机比特。
总结来说,RNG以非确定的方式从模拟源生成真随机比特,不保证高熵,而PRNG以确定的方式从数字源生成看起来随机的比特,并具有最大熵。
在随机性方面可能出现哪些问题呢?
一开始的Netscape浏览器的SSL代码是根据如下所示的伪码计算出128比特的PRNG种子的

这里的问题在于,PID和microseconds是可以被猜测的,如果可以猜到seconds,那么microseconds就只有10^6个可能的值
这是Log(10^6)的熵,大约20比特
另外,PID和PPID各15比特,所以本应有15+15=30比特的熵,但是在标注的1中,可看到,PPID和PID有3比特的重叠,所以只能产生15+12=27比特的熵
所以一共的熵为20+27=47比特,但是128比特的种子应该128比特的熵才对。这是熵源不理想的典型例子。
前些年有研究人员扫描整个互联网并从TLS证书和SSL主机中提取公钥,发现一些系统具有相同的公钥,私钥也非常相似。这是非常不合常理的,因为一般情况下,对于两个不同的大数n=pq,n'=p'q',p与p'不相等,q与q'不相等,但是研究人员发现经常会有n与n'不相等的情况下,p=p'
后面发现这其中的原因是,尽管使用了不错的PRNG,但由于在初次启动时会尽早生成公钥,所以在收集到足够的熵之前,如果基础熵源选取相同,那么不同系统中的PRNG会产生相同的随机比特。
会生成相同的密钥,是由于以下伪码中的密钥生成方案造成的

如果两个系统的种子相同,运行上述代码后会生成相同的p,q,也就会生成相同的n。而只有研究人员发现的,在不同密钥中存在共享素数,则是因为在密钥生成过程中注入了额外的熵,如下所示

如果两个系统使用相同的种子运行上述代码,会生成相同的p,但是由于prng.add_entropy()注入了熵,会得到不同的q
对于n=pq,n'=pq'的情况,会有什么为题呢?
这里的关键在于,通过计算n和n‘的最大公约数就可以恢复出p。
PRNG很常见,在不涉及密码学的场合中也有其身影,我们可以分为加密PRNG和非加密PRNG。非加密PRNG的作用一般是用于生成良好均匀的分布,常用于科学模型、视频游戏中,它只关心比特之间的概率分布的质量,但是不关心它的可预测性,所以在密码程序中不应使用非加密PRNG.
但是实际上,很多编程语言中都用的是非加密PRNG,比如libc中的rand,drand48,PHP中的rand,mt_rand,Python中的random模运算,Ruby中的Random类等。最常见的非加密PRNG就是Mersenne Twister(MT)算法了,它可以产生没好友统计偏差的符合一致分布的随机比特,但是这些比特是可预测的,给定一些MT产生的一些比特,可以预测接下来会出现哪些比特。
MT算法比加密PRNG简单多了,其内部状态是一个由624个32比特字组成的数组S,其初始值为S1,S2,...S624,运行一次后变为S2,...S625...其中的Sk+624可以通过如下计算:
![]()
初始状态的比特可以表示为输出比特之间的异或,反之亦然。
如果将其应用于密码系统则会造成危害。
MediaWiki使用随机性生成诸如安全令牌、临时密码等信息,按理来说,此处的随机性应是不可预测的,但是旧版本的MediaWiki使用了非加密PRNG来生成这些令牌和密码,其源码部分如下
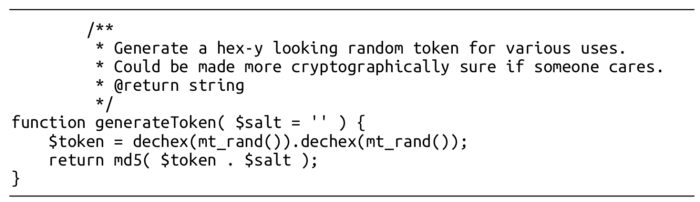
从代码中可以看到mt_rand()
这就是我们一直在说的Mersenne Twister,利用它攻击者就可以预测未来的令牌和临时密码。
1.Shoup V. OAEP reconsidered[C]//Annual International Cryptology Conference. Springer, Berlin, Heidelberg, 2001: 239-259.
3.https://link.springer.com/article/10.1007/s00145-003-0213-5
4.https://dl.acm.org/doi/10.1145/800070.802212
5.https://www.schneier.com/academic/archives/1998/01/cryptanalytic_attack.html
6.https://zh.wikipedia.org/wiki/A5/1
7.https://guidanceshare.com/wiki/Non-cryptographic_PRNG
8.https://www.mediawiki.org/wiki/Manual:Config_script/it
9.https://blog.cryptographyengineering.com/2012/03/09/surviving-bad-rng/
10.https://www.cs.umd.edu/class/fall2018/cmsc818O/papers/ps-and-qs.pdf


