-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
AI在生活中已经无处不在了,不论是高铁、机场的人脸识别还是指纹支付、语音助手等,都内置了AI技术。随着一项技术逐渐发展成熟,其安全风险就需要被考虑了。可能大家谈到AI安全的时候,最熟悉的就是对抗样本攻击,其本质是通过修改输入样本,来欺骗模型做出误分类的结果,这其实是属于模型安全领域。
事实上在谈及AI安全的时候,还有一个细分领域就是隐私安全,比如怎么保护数据不被泄露和模型逆向攻击。模型逆向攻击可以从模型中恢复出训练数据,如果此方案应用于人脸识别模型,恢复出人脸来,其危害是非常大的。
本文将会介绍模型逆向攻击的原理及其实现,并在基于MNIST训练的得到的CNN模型上进行攻击,最后成功复现,恢复出0~9的数字图像。此外,在文中代码复现部分,还会给出作者在复现论文算法时的一些经验,希望可以给大家带来启发。
除了模型逆向攻击以外,还有种攻击手段叫做模型提取攻击,看起来很相近,却是完全不同的两类攻击类型。
模型提取攻击是攻击者希望可以在本地恢复出目标模型,也就是说其攻击目的是窃取模型,我们知道大公司训练模型花了很大的资源的,不论是数据标注的人力成本还是训练模型花费的算力成本,大公司训练模型然后通过开放API查询接口,通过提供MLaaS来赚钱,如果攻击者能够窃取其模型,就是侵犯了其知识产权,影响其正常业务。攻击的示意图如下所示:
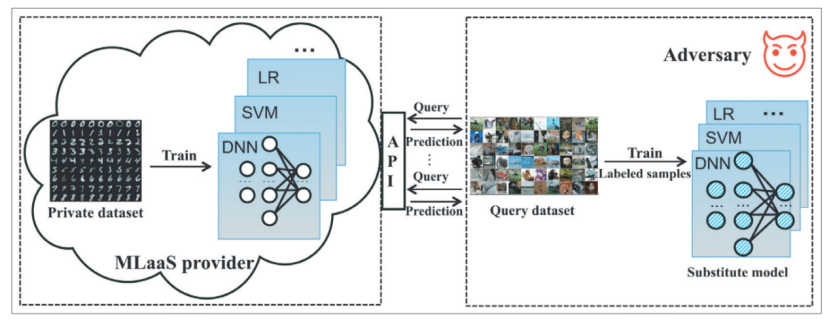
而模型逆向攻击是攻击者希望在不知道训练数据的情况下,通过推理得到训练数据,也就是说其攻击目的是为了得到隐私数据,可见两者区别是非常大的。
模型逆向攻击的效果如下所示:

这是Fredrikson等人做的实验结果,针对人脸识别系统,从其中恢复出训练数据集里的人人脸。上图中右边的图是通过攻击得到的人脸,右边的图是训练集中原来的人脸,可以看到,尽管存在一定差异,但是基本一致,说明该方案是可行的。我们就以Fredrikson等人为例,在理解了模型逆向攻击的原理后,根据论文中给出的算法进行复现,并针对MNIST数据集进行攻击。
我们要恢复的是训练集样本,而样本都是图像,图像是由像素组成的,其本质是由不同的像素强度组合起来得到的,所以我们要通过攻击得到训练集中的图像,本质上是要逆向的特征是构成图像的像素强度的完整向量,每个强度对应于 [0, 1] 范围内的浮点值。
我们假设攻击者知道他试图推断的向量中任何像素的确切值。假设具有n个分量和m个类别的特征向量,我们可以将分类器建模为以下函数:
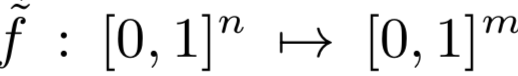
我们知道模型的输出是一个概率值向量,其中第 i 个分量对应于特征向量属于第 i 类的概率。我们将输出的第i个分量记作:
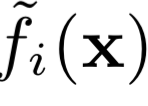
我们使用梯度下降来最小化涉及f~的损失函数,以进行模型逆向攻击。梯度下降通过迭代地将候选解向候选解的梯度的负值进行变换,来找到可微函数的局部最小值。攻击算法如下所示:

首先根据面部识别模型定义一个损失函数c和一个特定于具体情况的函数AuxTerm,它会把任何可用的辅助信息添加到成本函数中,比如当我们在对面部去模糊时就会将其实例化。
接着使用大小为λ的梯度步长对最多α次迭代应用梯度下降。在梯度下降的每一步之后,得到的特征向量被提供给一个后处理函数 Process,它可以根据攻击的需要执行各种图像处理,例如去噪和锐化。
如果候选者的损失函数在β次迭代中未能提高,或者成本至少与γ一样大,则下降终止并返回最佳候选者,此时就得到通过模型逆向攻击恢复出的训练集样本。
该方案要求可以计算得到梯度,在我们下一部分复现的时候,对于梯度消失的情况我们的攻击就失效了。
我们搭建一个标准的CNN模型:

并进行训练:

前面说过,我们的代码是基于《Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures》实现的,文中提出的算法是针对人脸识别模型进行攻击的,但是对于会给出梯度的其他分类器模型也是可行的,我们就会在实现论文提出的算法后将其应用于MNIST数据集。
MIFace类中关键的方法是infer,其需要接受初始化样本,如果不指定则默认用全零的数组作为初始输入,代码如下:
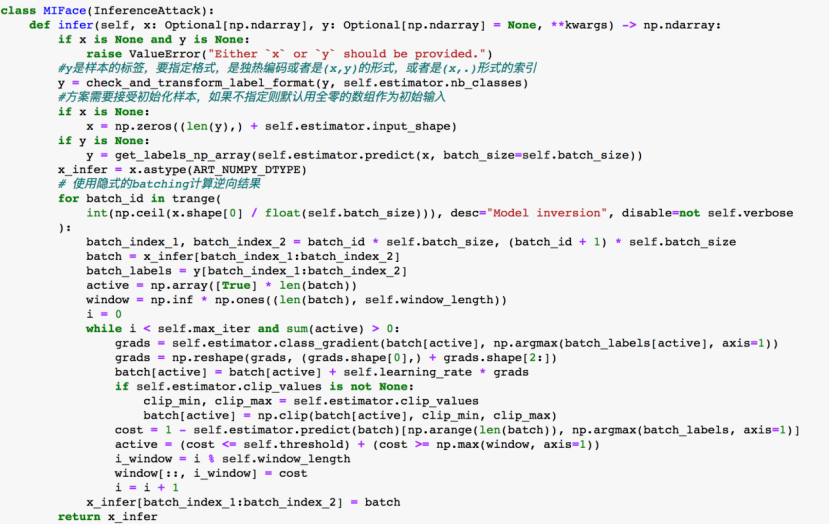
上面代码中很多都是用于处理数据格式、转换等问题的,关键的部分在红圈里面:
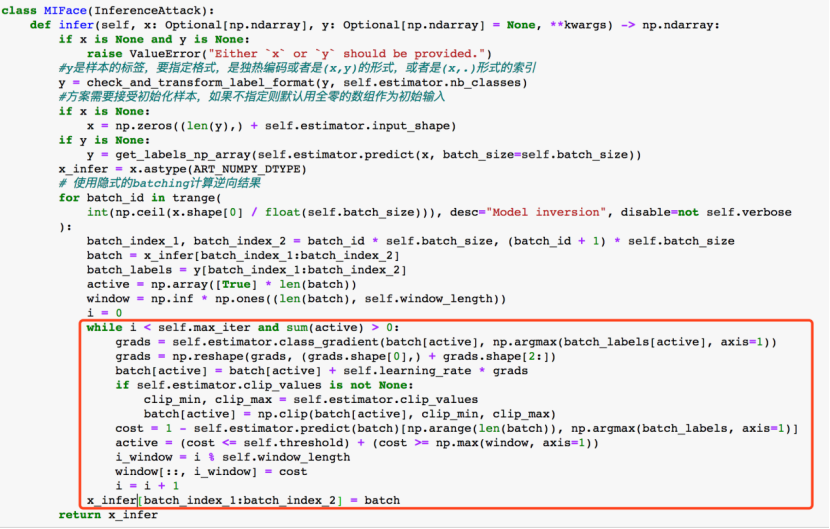
其对应的就是我们在上一部分介绍的论文给出的算法实现:

如果没有论文复现经验的话,看到这里大概已经清楚论文给出的算法和实际实现的算法还是有一定出入的。最明显的区别是论文会抽象出最本质的算法思想,而具体编程语言细节、数据处理细节并不关心,自己在复现的时候就需要注意这些细节;其次,可能论文要处理的问题和我们复现者要处理的问题不同,所以在理解清楚核心算法后自己在实现时需要结合实际情况,不应该全部照搬。
以损失函数的定义为例(第2行),论文给出的损失函数还有一项是AUXTERM(x),根据论文介绍,这是一个case-specific的函数,也就是说在不同case下,具体实现是不同的,它会把可用的信息加入成本函数中,辅助攻击,但是作者在做人脸去模糊的时候才给出了该函数的一个实例。此外,文中也说明了,如果没有辅助信息可用,则应该对所有x,直接定义AUXTERM(x)=0。因此,我们在实现的时候,可以直接略去这一项。
接下来应用MIFace执行攻击
![]()
我们的攻击目标是希望恢复出训练集中的样本,我们知道MNIST数据集中共有10类,从0到9,我们希望每种类别都可以恢复出来

不同的初始设置也会对攻击结果有影响,我们可以分别实验一下。
以全白的图像为初始样本开始发动攻击:

从上图的结果可以看到,可以看到在全白的图像上出现了gradient vanish的问题(即梯度消失问题),所以攻击是失败的。
再尝试以全黑的图像作为初始化样本:
![]()
有了前面的教训,我们这次先来打印梯度,确保没有梯度消失的情况:

然后发动攻击:

把结果可视化:

上面就是模型逆向攻击得到的图片,其实对于人类来说并没有明显的数字的特征。
那么我们不要取全黑,也不要全白,用居中的灰图作为初始样本:
![]()
同样先检查其梯度,确保没有梯度消失问题:

接下来发动攻击:

查看模型推理结果:

从上图的结果可以看到,从左到右,从上到下,隐约有0~4,5~9的轮廓了,说明攻击还是可行的。
我们再来看看以随机的图像作为初始样本会怎样:
![]()
首先检查其梯度,确保存在:

发动攻击:

可视化结果:

这次推理得到的结果也比较差,几乎看不出来0~9的样子。
全黑、全白、居中的灰图以及随机生成的样本都用作初始化了,其中灰图比较好。那么有没有更好的办法呢?
回顾下模型逆向攻击的假设,攻击者希望推理出训练集中的样本,但是他是知道测试集的样本的,我们前面的几次攻击都没有利用这一先验知识。那么我们可以考虑将测试集样本求个平均,然后作为模型逆向攻击的初始样本:
![]()
确保梯度存在:

发动攻击:

可视化模型逆向攻击的结果:

每张图片基本都可以看到对应类别数字的轮廓了,说明模型逆向攻击成功了。
通过这五组对比实验,给我们的启发是在进行攻击时,要时刻注意攻击的前提、场景以及对攻击者能力的假设,并利用好先验知识,这样能更好地实施攻击。
1.Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures
2.Algorithms that remember: model inversion attacks and data protection law
3.Improved Techniques for Model Inversion Attacks
4.Stealing Machine Learning Models via Prediction APIs
5.Model Extraction Attacks and Defenses on Cloud-Based Machine Learning Models
6.https://github.com/google-research/cryptanalytic-model-extraction


