-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
#前言
目前大量物联网设备及云服务端直接暴露于互联网,这些设备和云服务端存在的漏洞(如:心脏滴血、破壳等漏洞)一旦被利用,可导致设备被控、用户隐私泄露、云服务端数据被窃取等安全风险,甚至会对基础通信网络造成严重影响。为了促进物联网领域的安全研究,研究人员制作了UNSW-NB15数据集,这是一个基于物联网的网络流量数据集,对正常活动和恶意攻击行为进行了不同的分类。本文将基于该数据集,应用AI领域的典型技术,包括决策树、随机森林、逻辑回归、多层感知器等进行检测,希望师傅们可以从中了解AI技术应用于安全领域的典型流程,包括数据预处理、数据转换、交叉验证等,同时提升对物联网安全的新的认识。
#数据集
本次用到的数据集是UNSW-NB15,这是一个基于物联网的网络流量数据集,由新南威尔士大学堪培拉网络靶场实验室的 IXIA PerfectStorm工具创建,用于生成真实现代正常活动和合成当代攻击行为的混合数据集。 它们使用tcpdump 工具捕获 100 GB 的原始流量(例如 Pcap 文件)。
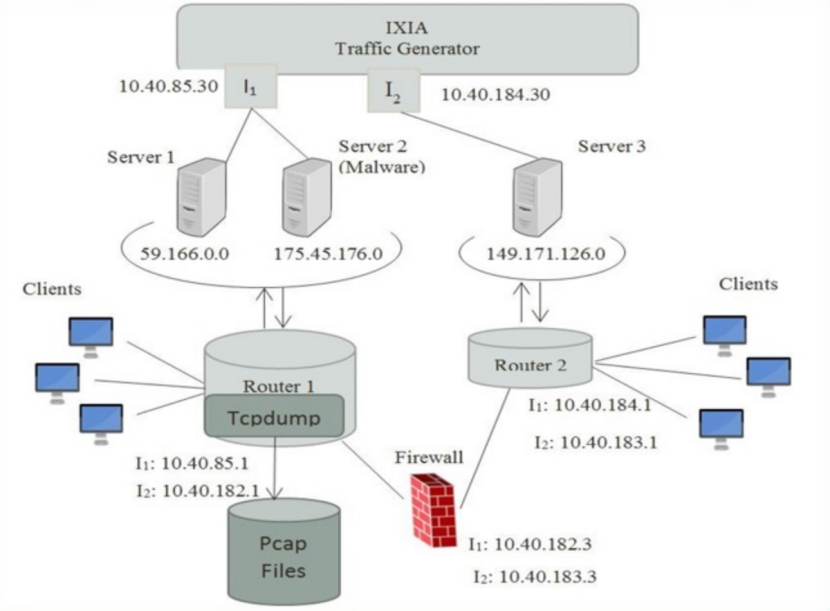
该数据集有九种类型的攻击,即 Fuzzers、Analysis、Backdoors、DoS、Exploits、Generic、Reconnaissance、Shellcode 和 Worms,当然为了方便大家使用,已经做了整理,把特征、标签都统计到了csv文件里。
如果希望详细了解该数据集的信息的话,可以参考[2][3][4]论文
该数据集中的一部分被做为训练集和测试集,即 UNSW_NB15_training-set.csv 和 UNSW_NB15_testing-set.csv。训练集中的记录数为 175,341 条记录,测试集中的记录数为 82,332 条记录,分别来自不同攻击类型、恶意和正常数据。
#数据预处理
导入所需库文件
数据集中的数据包括9种攻击类型,分别是Fuzzers, Analysis, Backdoors, DoS, Exploits, Generic, Reconnaissance, Shellcode和Worms。在csv文件最后的一列是标签,0代表郑,1代表攻击
加载训练数据UNSW_NB15_training.csv,检查前5行

可以看到前5行的记录都是正常的
加载数据后我们首先检测是否存在缺失值
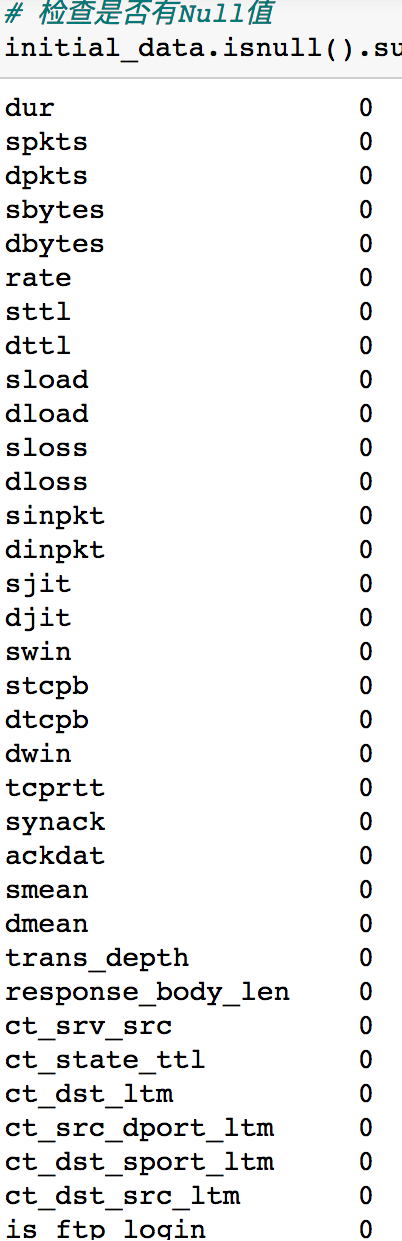
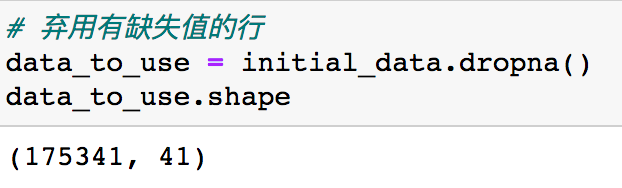
面对存在缺失值的情况,最简单的方法就是直接启用包含缺失值的整行和整列
然后看看数据是否平衡,一方面是看9种攻击类型是否平滑(y1指代这方面的标签),一方面是看正常和恶意的数据量是否平衡(y2指代这方面的标签)
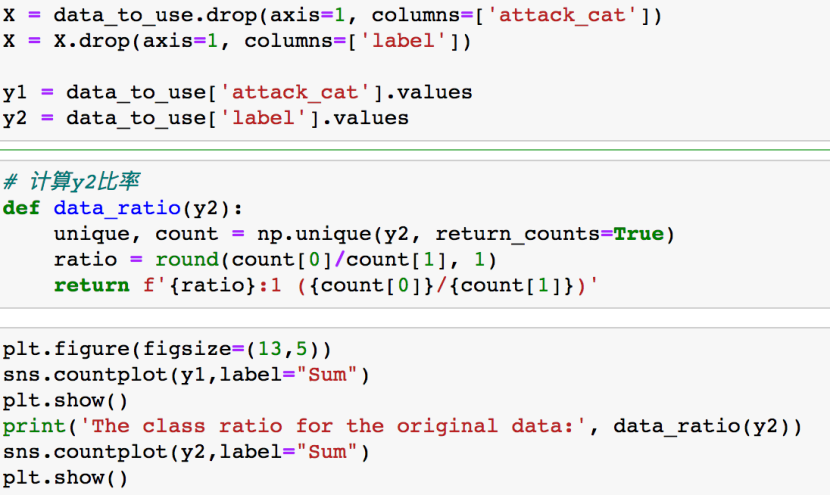
结果如下
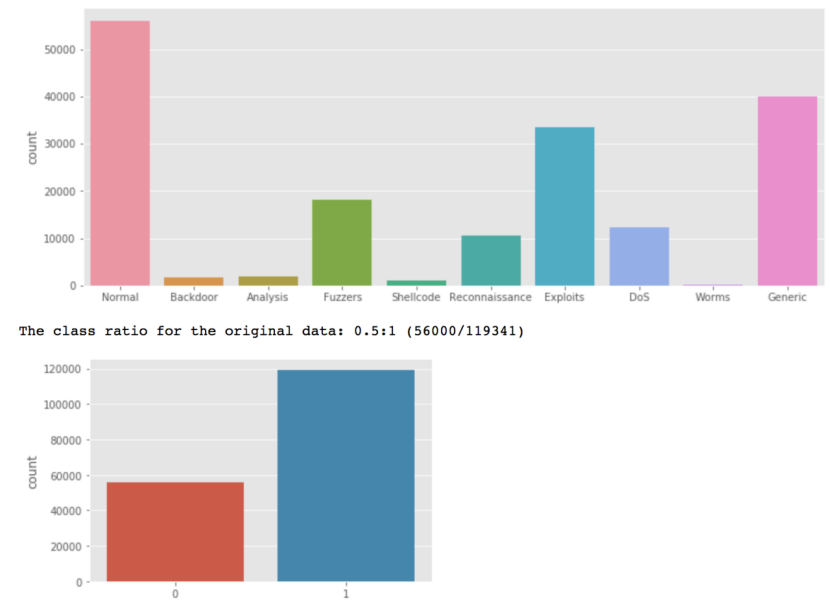
可以看到数据集并不平滑,不过并不严重,我们继续往下分析
本来是需要手动拆分训练集和测试集的,不过UNSW_NB15已经拆分好了,比率为7:3
训练集和测试集分别在UNSW_NB15_training-set.csv 和 UNSW_NB15_testing-set.csv
如果需要手动拆分的话,使用下面的代码就可以了
![]()
我们加载测试集供后续使用

#数据转换
接下来需要转换数据
首先需要确定哪些列是分类数据(categorical),哪些列是数值数据(numerical)(分类数据也叫qualitative data或是Yes/No data,是定性的,而数值数据是定量的)

分别将其打印
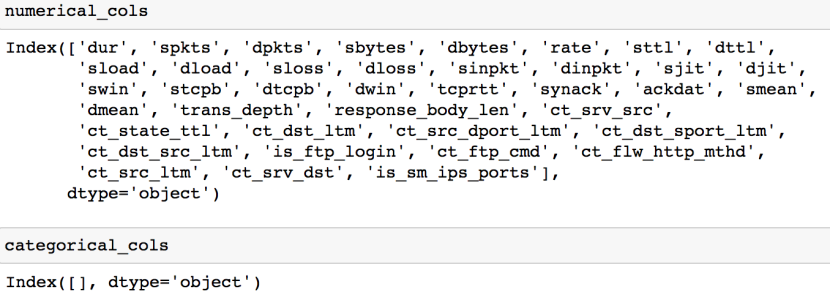
对于分类数据应用OneHotEncoder,将其编码为独热数值数组
对于数值数据应用StandardScaler,通过去除均值和缩放到单位方差来标准化
构造ColumnTransformer对象,在X_train上进行fit即可
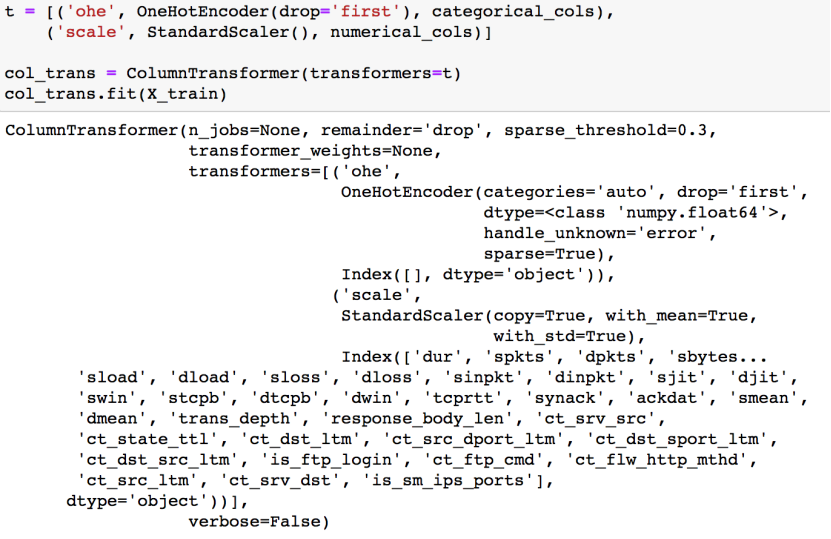
每个transformer分别转换x,将结果拼接起来
![]()
对测试集也进行同样的处理
![]()
转换后的数据不再是dataframe结构,而是类似于数组的结构

我们同样还需要转换y1,y1中一共有9类

我们直接用LabelEncoder就可以了,其用于规范化标签,使处理对象仅包含0和类别数-1 之间的值
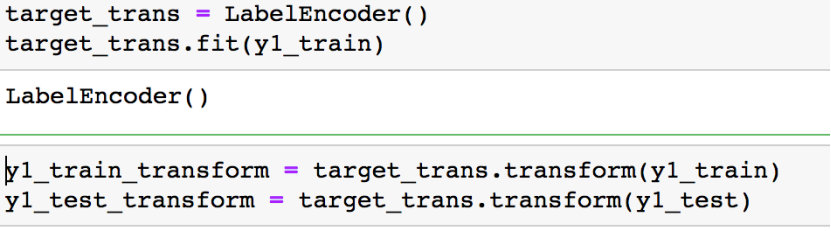
截止目前,数据部分已经处理完成了,接下来就是训练模型了
#交叉验证
我们训练模型后,会使用5折交叉验证(cross validation,CV)进行验证,评估模型的指标包括准确率、准确率、召回率、F1 分数、ROC 的 AUC 值;然后使用测试集评估模型看看效果如何
我们以逻辑回归分类器为例

查看交叉验证结果
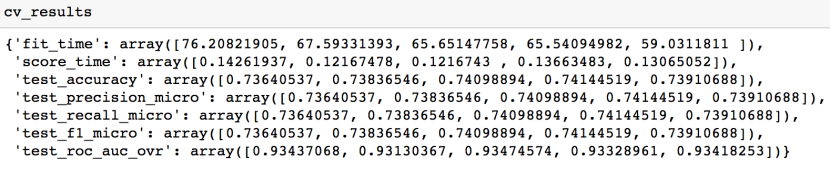
因为是5折交叉验证,所以每个指标都有5组数据,基本上我们会使用平均值来衡量校验验证的评估结果
比如打印出平均的准确率

#模型测试
在测试集上进行测试

结果如下
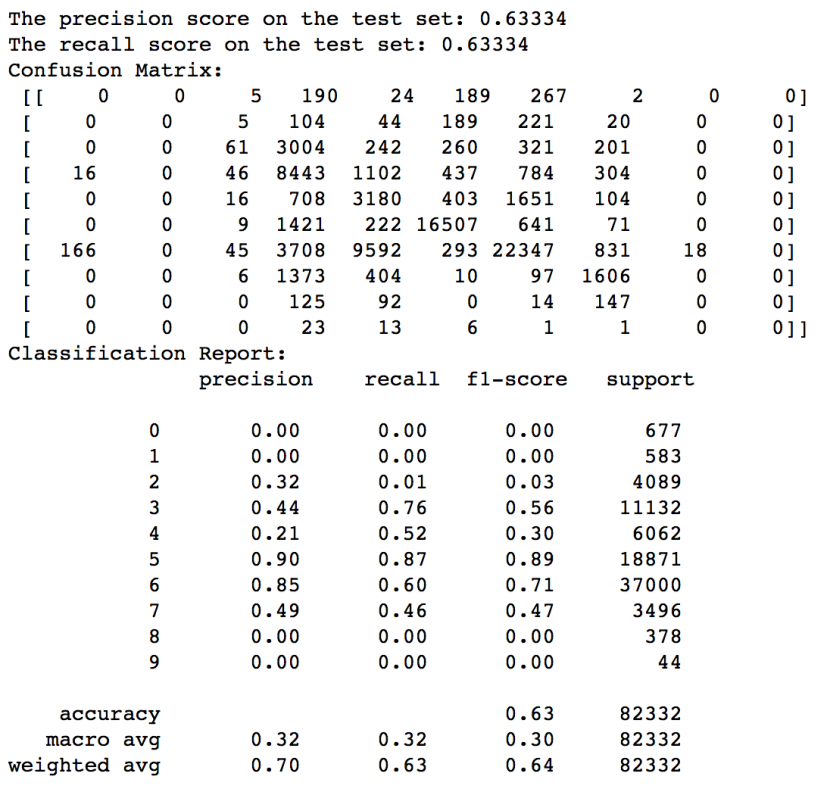
precision是精确率,也称作查全率,等于tp/(tp+fp);这是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本
recall是查准率,也称召回率,等于tp/(tp+fn);这是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了
从计算公式可以看出,其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数
如果看单个指标都过于片面,可以通过f1分数来评估模型性能,f1是recall和precision的加权平均,在上面可以看到在0.64左右
#其他机器学习方法
在sklearn已经实现了很多机器学习模型,我们只需要一条代码就可以换模型,除了逻辑回归之外,还可以试试决策树和随机森林

打印出模型的超参数

然后重复之前的步骤,来看看结果如何
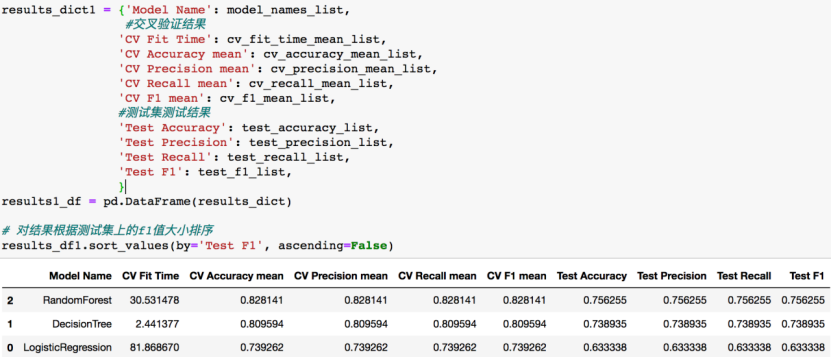
可以看到,随机森林的效果是相对而言比较好的
#多层感知器
以上三个分类器都属于传统的机器学习方法,那么接着我们试试MLP,这是一种前向结构的神经网络。
结果如下
![]()
把这四种分类器放在一起看看哪种效果更好

可以看到随机森林的效果还是最好的。这也给我们一个提示,虽然现在深度学习、神经网络
是AI的最火热的技术,但是这并不意味着在所有任务上都是万能的,它们更大的优势是在处理海量数据、复杂任务上,对于一些基础的任务,可能传统的机器学习方法会有更好的效果。
相关实验:机器学习之RF
#参考
1.https://www.unsw.adfa.edu.au/unsw-canberra-cyber/cybersecurity/ADFA-NB15-Datasets/
2.UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set).
3.The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 dataset and the comparison with the KDD99 dataset
4.Novel geometric area analysis technique for anomaly detection using trapezoidal area estimation on large-scale networks
5.http://www.caict.ac.cn/kxyj/qwfb/bps/201809/P020180919390470911802.pdf
6.《机器学习》


